
a16z投了一家“不看简历”的AI招聘公司
a16z投了一家“不看简历”的AI招聘公司5月6日,主营AI招聘的初创公司Ethos宣布完成2275万美元(约合人民币1.55亿元)的A轮融资,由a16z领投,General Catalyst、XTX Markets、Evantic Capital和Common Magic跟投。
来自主题: AI资讯
9276 点击 2026-05-07 22:35
 搜索
搜索
5月6日,主营AI招聘的初创公司Ethos宣布完成2275万美元(约合人民币1.55亿元)的A轮融资,由a16z领投,General Catalyst、XTX Markets、Evantic Capital和Common Magic跟投。
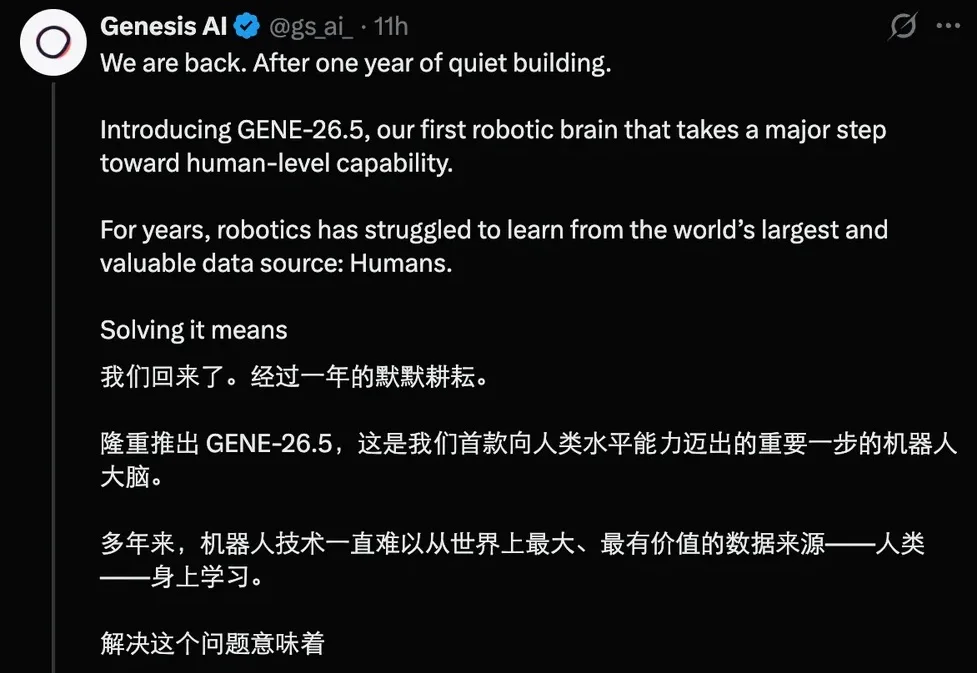
那个一句话生成完整物理世界、做出 GitHub 最大开源机器人项目的团队,又出手了。
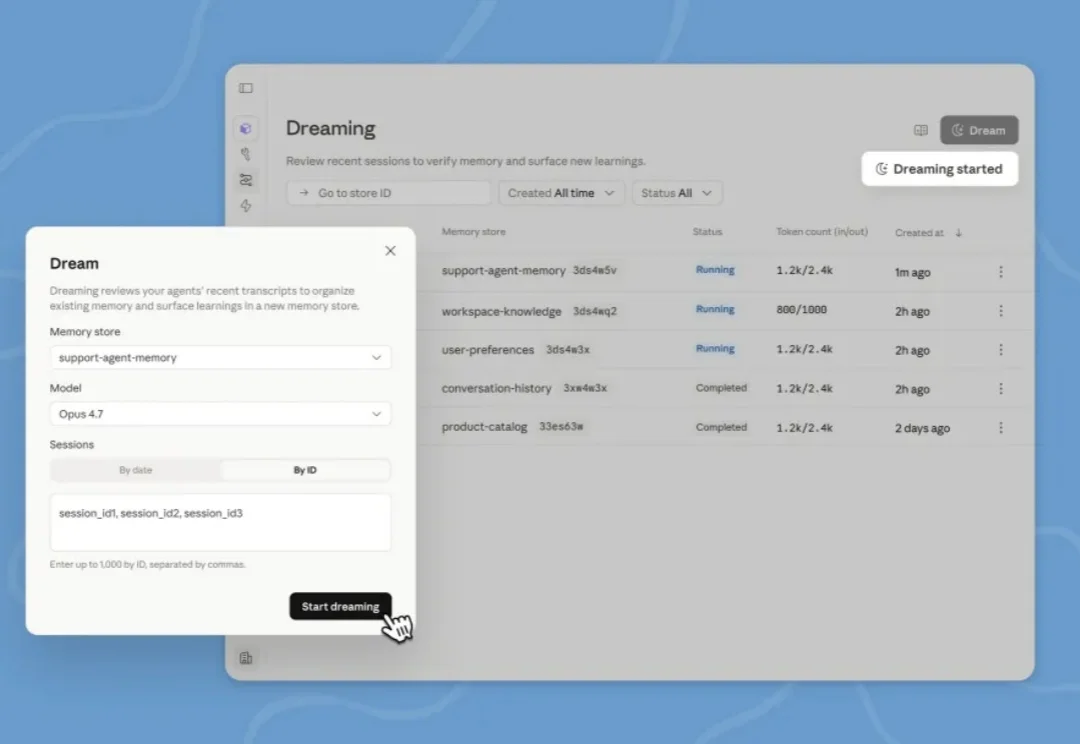
之前 Claude Code 源码泄露的时候,大家惊奇的发现,里面有一个正在开发的功能:做梦

AI圈有个怪现象: 模型越来越强,确实是好事;但随着AI用法越发多样,用起来的门槛却越来越高。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。

Anthropic最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。
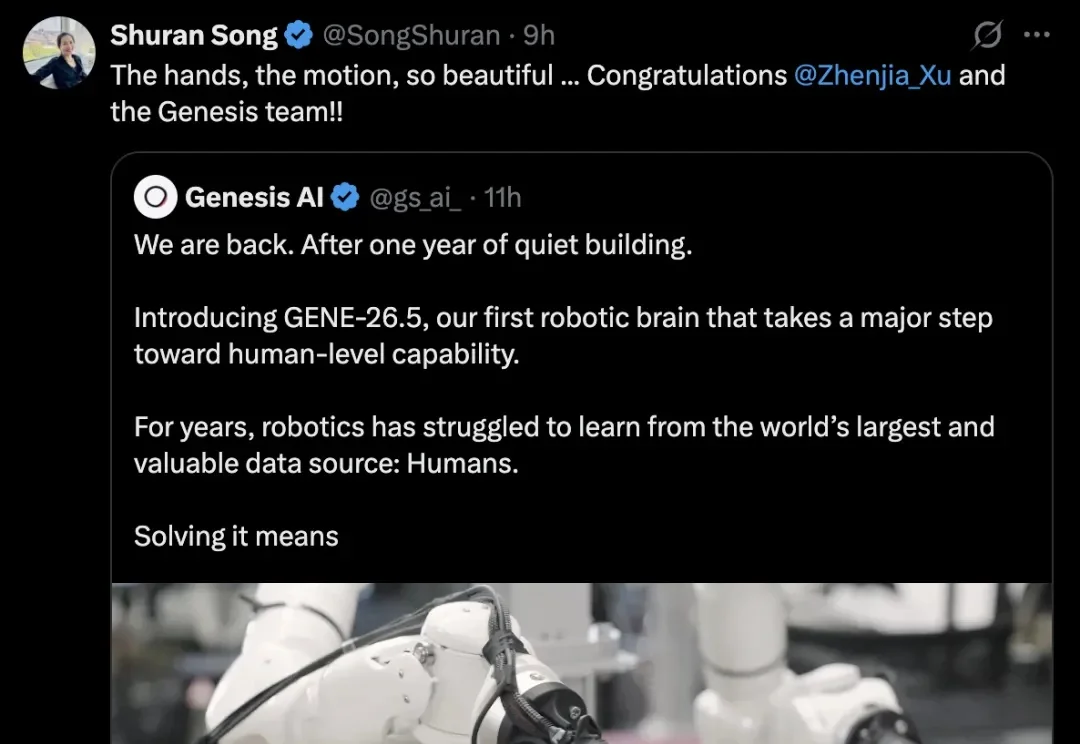
看过的人已经傻眼了,因为这可能是今年为止最炸的机器人demo。
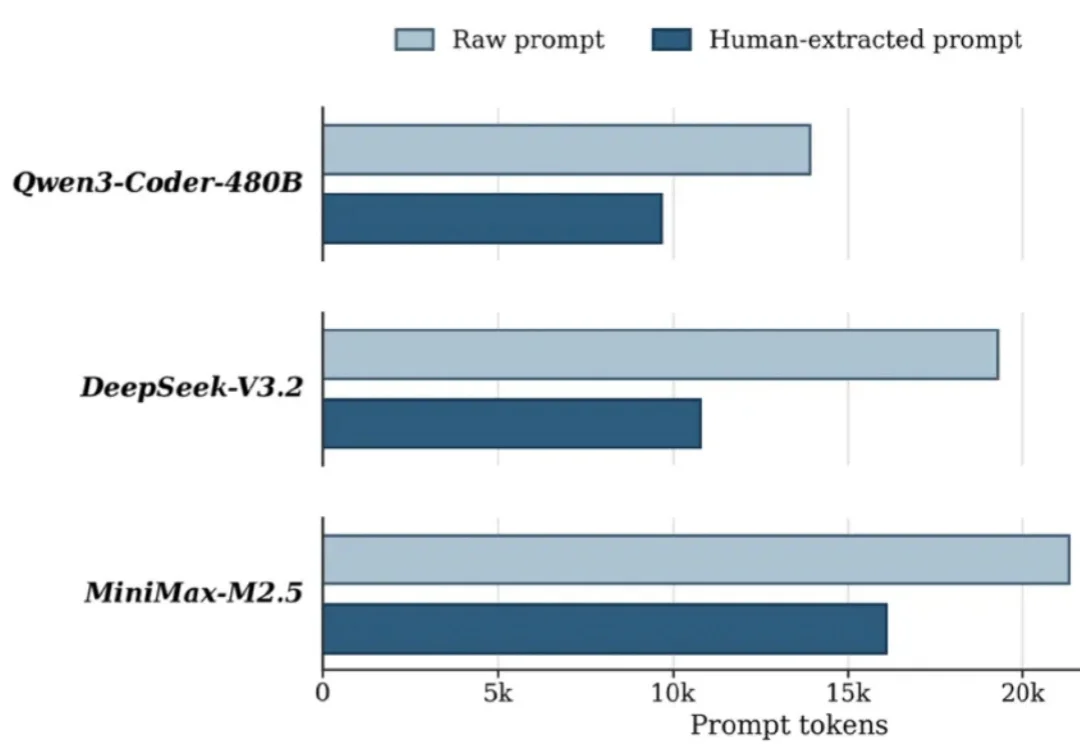
随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。

Claude开发者大会来了!这一次,Anthropic让Agent学会了「做梦」,两次干活的间隙自动反刍记忆、自我进化。配合多Agent兵团作战和自动评分官,AI任务完成率直接暴涨6倍。