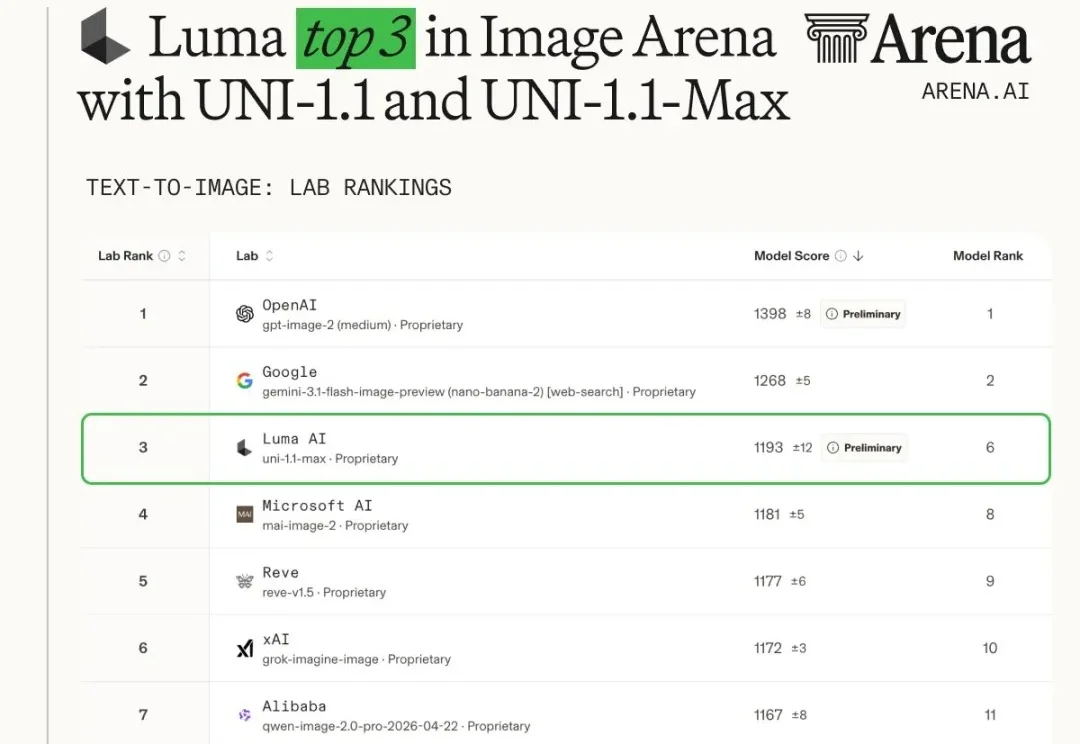
Luma Uni-1.1 API开放,图像模型榜单第三,文字渲染直逼GPT image 2
Luma Uni-1.1 API开放,图像模型榜单第三,文字渲染直逼GPT image 2今年以来,图像生成模型的迭代节奏明显加快。
来自主题: AI技术研报
10186 点击 2026-05-06 15:17
 搜索
搜索
今年以来,图像生成模型的迭代节奏明显加快。
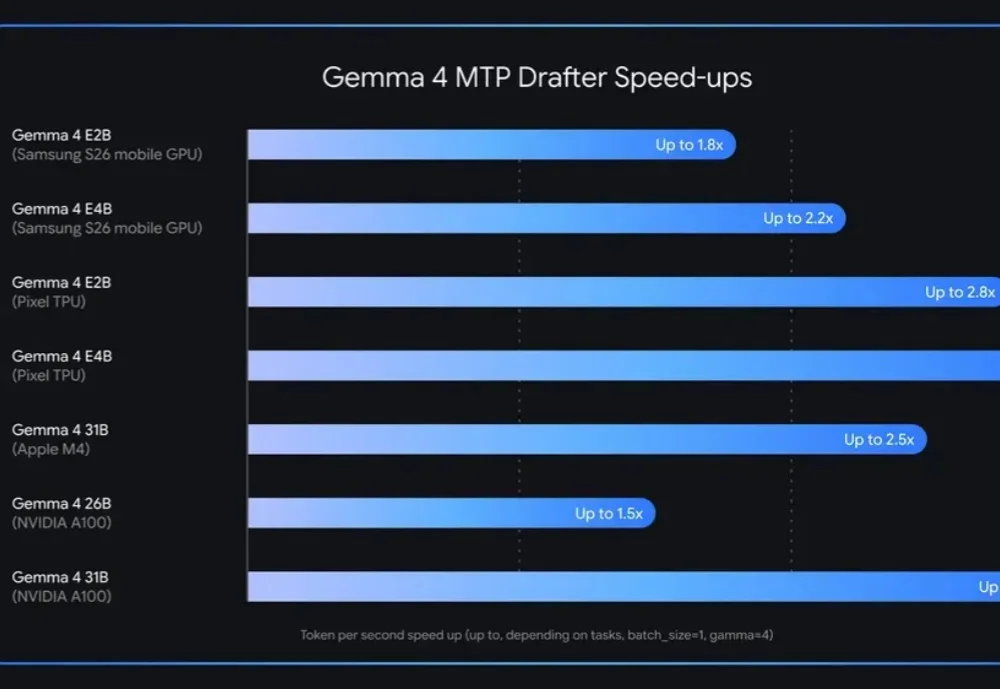
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。

4 月 9 日,Anthropic 在 X 上宣布 Claude Managed Agents 上线。同一天,一位 ID 叫 @jiayuan_jy 的中国创业者也发了一条推,“We created the open source version of Claude Managed Agents. Introducing Multica.”
我发现囤Agent的Skills有瘾, 今天刚装了一大堆同类Skill,还没用熟就想提前知道这类里最好的到底是哪一个。转头又发现某个佬推荐了自留的20个Skills,回回路过我都忍不住点进去看。
如果您经常用Claude Code、OpenCode、OpenClaw这类Agent框架,大概率会遇到一种不稳定现象:同一个Skills,用Claude能跑,换成Qwen就不行了;在Claude Code里稳定的流程,换到OpenClaw可能输出格式崩掉;在作者环境里正常的脚本,到了自己机器上可能因为缺依赖进入反复报错。
真的,你有过这种时刻吗。
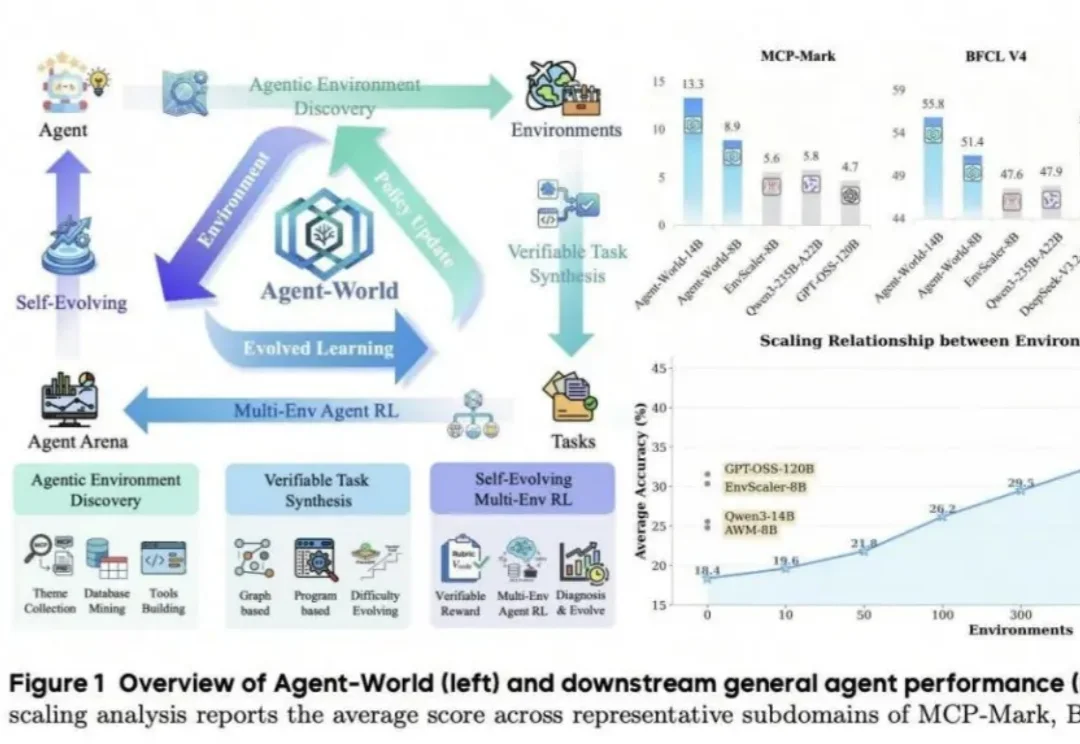
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。
最近发现 GitHub 上有个 4 万多 Star 的开源项目(system_prompts_leaks),干了一件事:把市面上几乎所有顶级 AI 产品的 System Prompt,全部扒了出来。ChatGPT、Claude、Gemini、Grok、Claude Cowork、Codex、Perplexity....你能叫得出名字的,基本都有。

自学习 AI 的融资神话,正在告诉我们一件事——这场 AI 军备竞赛,连研究员本身都要被「卷」进去了。 作者|桦林舞王 编辑|靖宇 1956 年,一批科学家聚在达特茅斯,第一次正式讨论「机器能否思考」
一位中国开发者自称用5个Claude AI代理并行工作,独自承接原本需要5-8人团队的外包项目,月入2.67万美元。这些数字来自B站视频的二次转述,无法独立核实——但真正值得注意的,是他描述的技术架构已经写进了Anthropic官方文档。