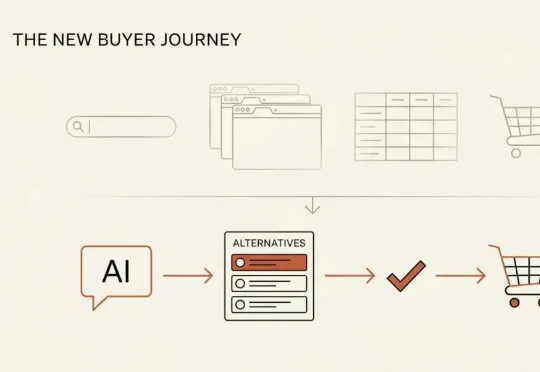
怎么让 ChatGPT 在别人搜你对手名字时,推荐你
怎么让 ChatGPT 在别人搜你对手名字时,推荐你以前:搜 Google → 开 8 个标签页 → 对比功能 → 约演示 → 买。现在:搜那个默认大牌 → 再搜「某某大牌 的替代品」→ 从冒出来的 3 个名字里挑一个 → 约演示 → 买。整条对比研究,被 AI 一次答复压缩成了「三选一」
来自主题: AI资讯
8151 点击 2026-07-06 10:25
 搜索
搜索
以前:搜 Google → 开 8 个标签页 → 对比功能 → 约演示 → 买。现在:搜那个默认大牌 → 再搜「某某大牌 的替代品」→ 从冒出来的 3 个名字里挑一个 → 约演示 → 买。整条对比研究,被 AI 一次答复压缩成了「三选一」
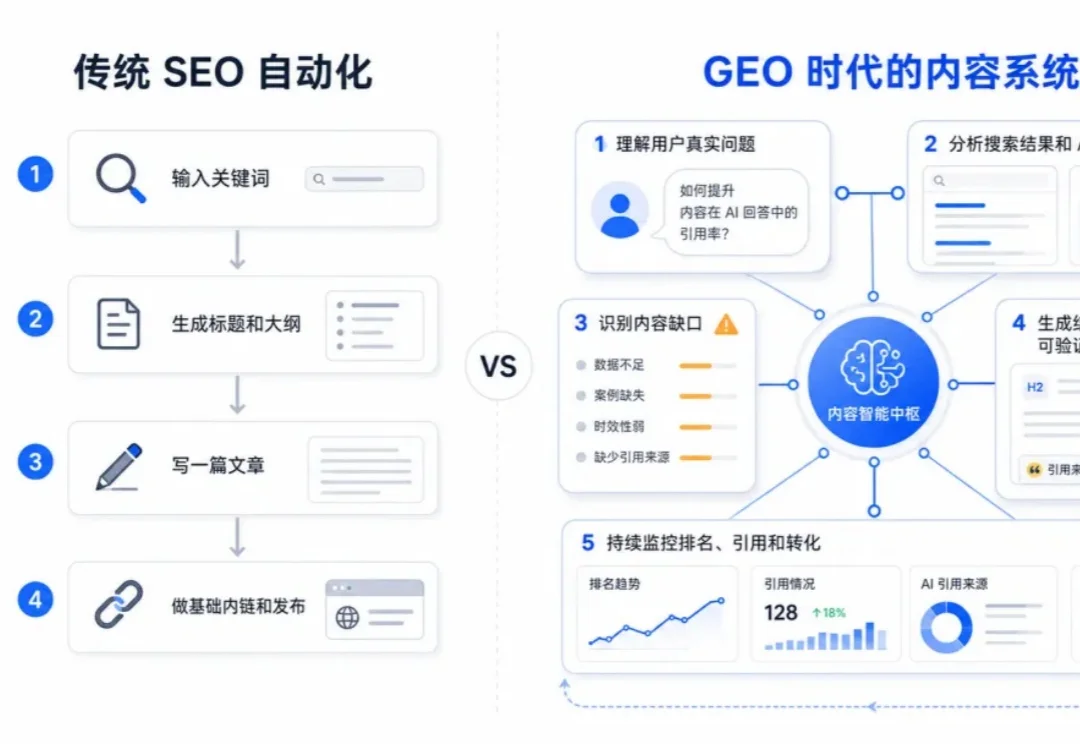
最近,有很多朋友来请教我们一个问题,GEO到底要怎么做,才能让生成的内容质量更高。

6 月 23 日,腾讯云发布全新边缘 Web 与 AI Agent 托管平台 Tencent Cloud EdgeOne Makers(以下简称Makers),进一步强化面向Agent时代的 AI 全链路布局。

有两个站在硅谷最深处的AI天才,乔治·霍兹(George Francis Hotz)和卡帕西(Andrej Karpathy),为了AI编程这件事吵起来了,而他们背后,正是硅谷乃至美国AI市场的撕裂。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,
5月23日,分众传媒在投资者互动平台回应了一个提问:公司已控股钛镁时代(品牌名钛镁AI),持股51%,投资金额数千万元。
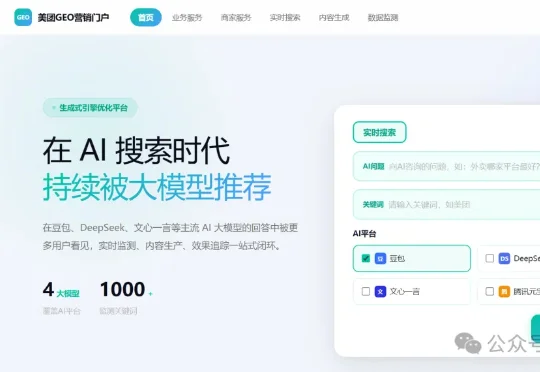
前段时间我写了一篇关于美团入局GEO的文章,解读了本地生活未来GEO的布局方向,后续的结果也被我预测到了。就在前几天,美团发布了自己的GEO营销系统:

当你某天一觉醒来,发现自己被困在布满屏幕的房间里,每个屏幕中播放的不是你感兴趣的内容,而是无穷无尽的广告。想跳过?先支付费用。

这几天有好几个小伙伴@我说,我的开源工具在他们问 AI 的时候被主动推荐了,啥也没做居然可以被收录,想着要不花一个小时把内容结构化整一整,应该会更好,于是整好以后,快速发了一个速记推,但是内容结构不清晰,想着大家很感兴趣,那要不就整一个结构清晰的文章便于沉淀和查找。

UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。