唐杰预告「GLM史诗级升级」!技术论文入选顶会COLM
唐杰预告「GLM史诗级升级」!技术论文入选顶会COLM炒股到现在最对不起的,就是家人。
来自主题: AI技术研报
8361 点击 2026-07-23 10:39
 搜索
搜索
炒股到现在最对不起的,就是家人。

这是今天 AI 圈最大的瓜。 OpenAI 的神秘模型,主动对开源平台 Hugging Face 发起了攻击。Hugging Face 随后追踪展开还击,用的是智谱的开源模型 GLM 5.2。闭源模型一举攻破开源社区,社区用开源模型自救,这离谱的剧情听起来都能拍一部电影了。

最近手头在测一个新模型,叫 Macaron-V1。说实话一开始没抱太大期待,打着「个人智能体」旗号的产品这两年太多了,大多数打开之后还是那套老配方:一个聊天机器人,外面挂几个插件。但测了三四天下来,发现这个模型的思路跟我预想的不太一样,值得认真写一篇。
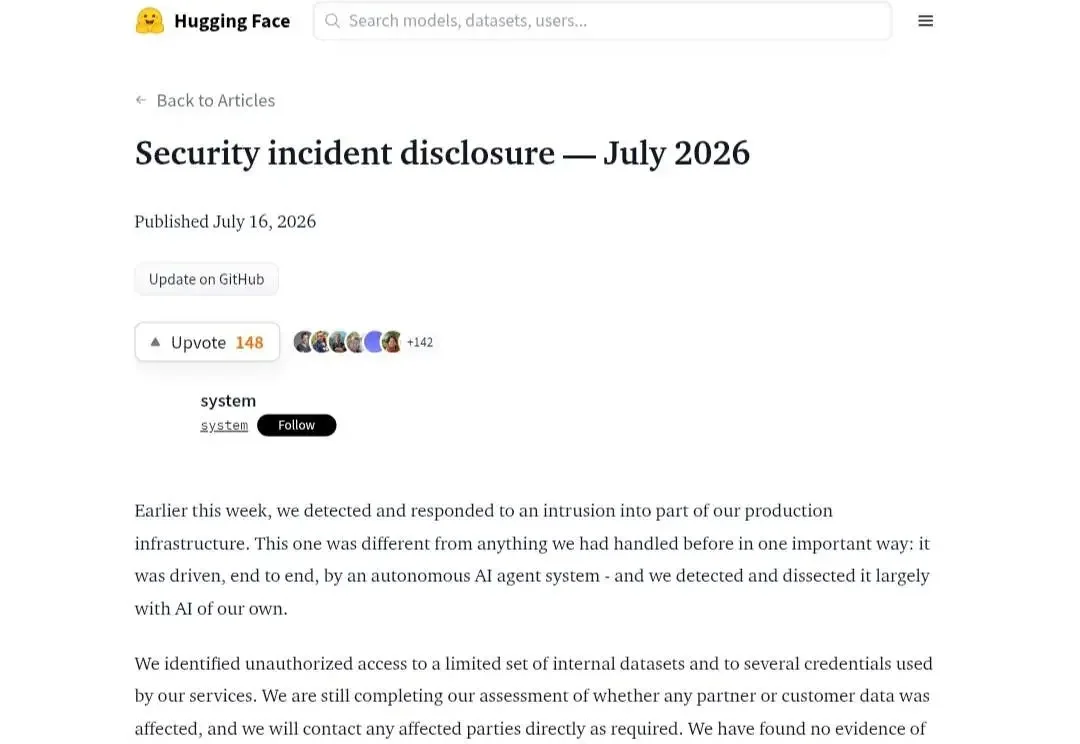
近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。

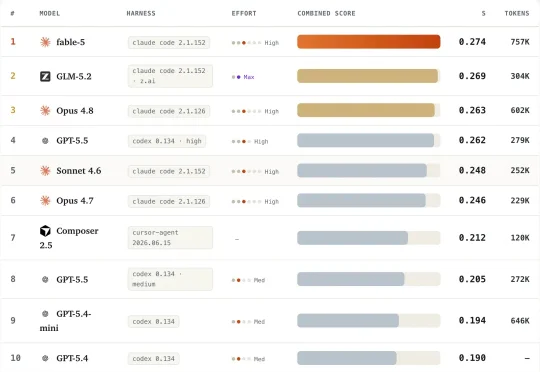
Databricks的联合创始人兼CEO Ali Ghodsi最近整了一个大活。公司有1.1万名员工,AI相关的开销越来越高,到底该用哪个模型搭配哪种执行框架,才能在省钱的同时保住效果?自己动手做了一次大规模测试。这次测试基于Databricks真实的业务代码,覆盖3家主流云厂商,由3000多名工程师的实际工作产出支撑,涉及多种编程语言和任务类型。

2026年7月11日,智谱创始人唐杰,在智谱发布了主题为《巨浪已来》的内部信。过去半年来,智谱收获了创立以来的高光时刻:市值较半年前上市初期涨了10倍,并在2026年6月,跻身“万亿港元俱乐部”——这个数字,是百度市值的近3倍,并且超过了小米。7月8日,首批股票解禁后,智谱依然稳住了股价。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。
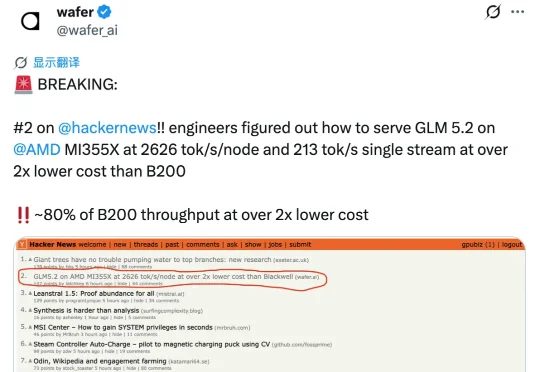
GLM 5.2,用AMD芯片也能跑出来了,而且成本只要英伟达的一半。这是推理优化公司Wafer这周公布的一组数据。Wafer用AMD的MI355X芯片跑最新开源模型GLM 5.2,单节点吞吐做到2626 tok/s,单流吞吐也跑到了213 tok/s。
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。
上个月 GLM 5.2 发布的时候,我写过一篇文章,说智谱家出了个叫 ZCode 的编程工具,专门给 GLM 5.2 做开发环境。当时就是简单上手体验了一下,觉得还行,是个正经的 AI 编程产品。