
奥特曼亲自上阵,Images 2.0登顶王座!大米刻字,生图跨入GPT-5时代
奥特曼亲自上阵,Images 2.0登顶王座!大米刻字,生图跨入GPT-5时代今夜,ChatGPT Images 2.0震撼上线,成为首个「会思考」的图像AI。奥特曼直呼这是从GPT-3到GPT-5的飞跃。它不仅能精准听懂中文指令、渲染复杂UI,甚至能在米粒上刻字。
来自主题: AI资讯
9952 点击 2026-04-22 10:04
 搜索
搜索
今夜,ChatGPT Images 2.0震撼上线,成为首个「会思考」的图像AI。奥特曼直呼这是从GPT-3到GPT-5的飞跃。它不仅能精准听懂中文指令、渲染复杂UI,甚至能在米粒上刻字。
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。

吴恩达又出新课了,这次的主题是—Agentic AI。 在新课中,吴恩达将Agentic工作流的开发沉淀为四大核心设计模式:反思、工具、规划与协作,并首次强调评估与误差分析才是智能体开发的决定性能力:
凌晨1点,OpenAI突然扔出Sora 2核弹,AI视频迎来「GPT-3.5时刻」!一大批惊艳Demo放出,物理智能提升一大截,首次实现音画同步,人物一致性、可控性刷新SOTA。但最绝的还是Sora App,它的问世,或将彻底重塑短视频社交媒体的交互逻辑与社区互动方式。

DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。

AI时代的基建狂潮来了!Anthropic联合创始人Tom Brown直言:人类正踏上一场规模超越阿波罗登月、曼哈顿计划的算力竞赛。他,曾经线代只考70多,6月自学成才,加入OpenAI打造GPT-3,创立Anthropic……一路开挂堪比韦小宝,他正是AI时代最燃的注脚!

Anthropic 联合创始人 Jared Kaplan 是一名理论物理学家,研究兴趣广泛,涉及有效场论、粒子物理、宇宙学、散射振幅以及共形场论等。过去几年,他还与物理学家、计算机科学家们合作开展机器学习研究,包括神经模型以及 GPT-3 语言模型的 Scaling Law。

从「与GPT-3.5畅聊」到「ChatGPT」,OpenAI团队如何在混乱中拍板上线、又怎样被用户「点赞」调教成「赛博舔狗」?从产品发布、命名内幕、团队文化到AI时代核心竞争力,深度访谈揭开幕后全过程!

“不用纠结,现在是否到了具身的 GPT-3 时刻。”
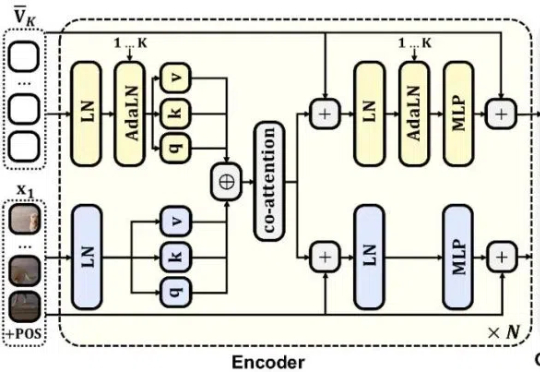
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。