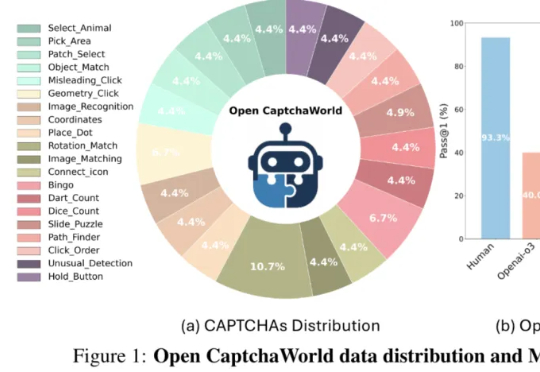
GPT-4o连验证码都解不了??SOTA模型成功率仅40%
GPT-4o连验证码都解不了??SOTA模型成功率仅40%当前最强多模态Agent连验证码都解不了?
来自主题: AI技术研报
8771 点击 2025-06-05 10:39
 搜索
搜索
当前最强多模态Agent连验证码都解不了?
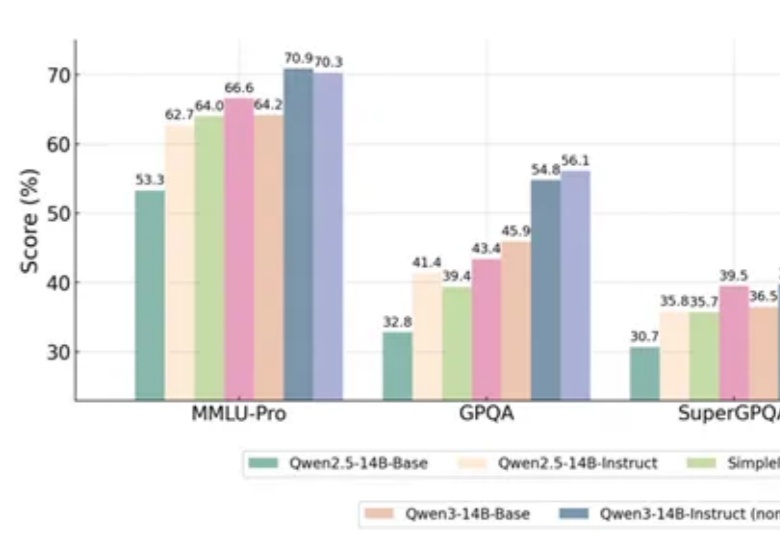
一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
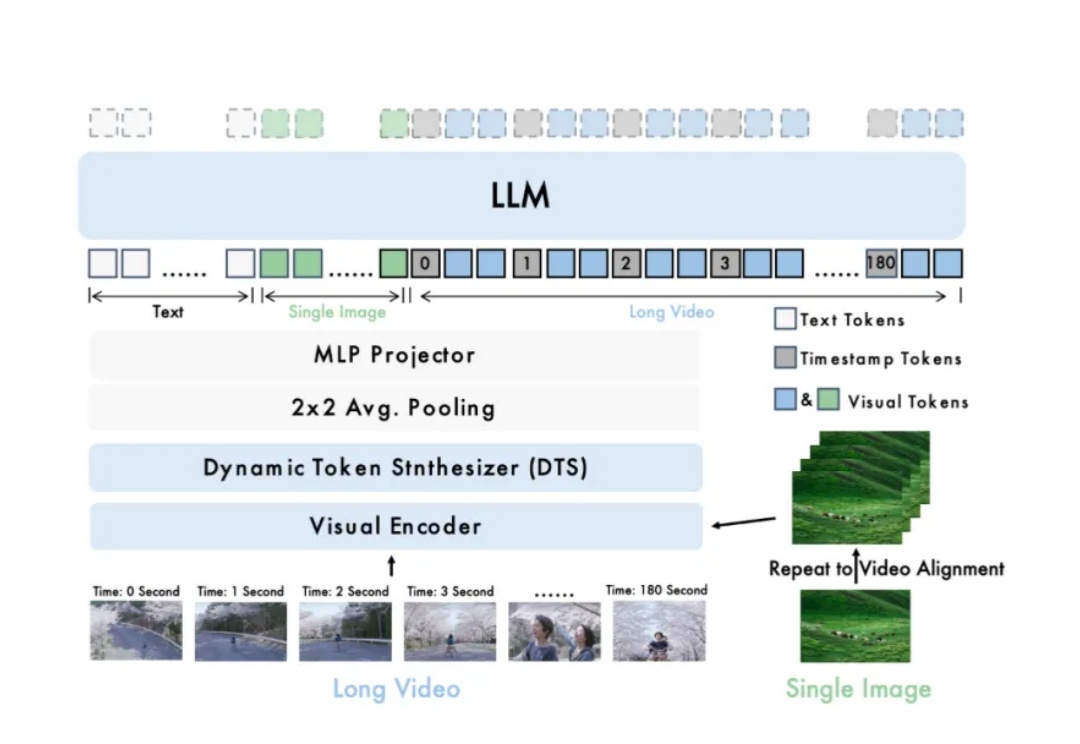
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。

不久前,GPT-4o 的最新图像风格化与编辑能力横空出世,用吉卜力等风格生成的效果令人惊艳,也让我们清晰看到了开源社区与商业 API 在图像风格化一致性上的巨大差距。
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

最顶尖的AI模型,做起奥数题来已经和人类相当,那做物理题水平如何呢?港大等机构的研究发现:即使GPT-4o、Claude 3.7 Sonnet这样的最强模型,做物理题也翻车了,准确率直接被人类专家碾压!
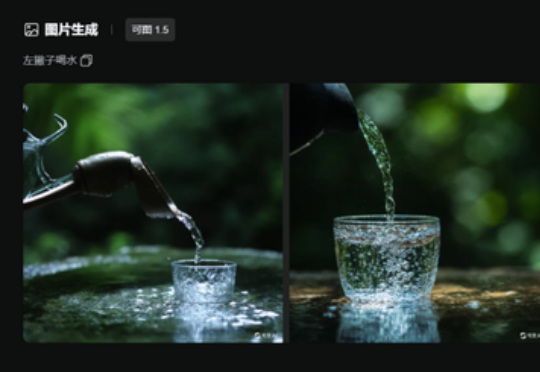
前几天在论坛上看别人激烈辩论 AI 是否会取代工程师,突然有人在回复中冷不丁的抛出一个评论: 别说那么多废话,先让 AI 画个左撇子出来。 这是个什么问题?

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
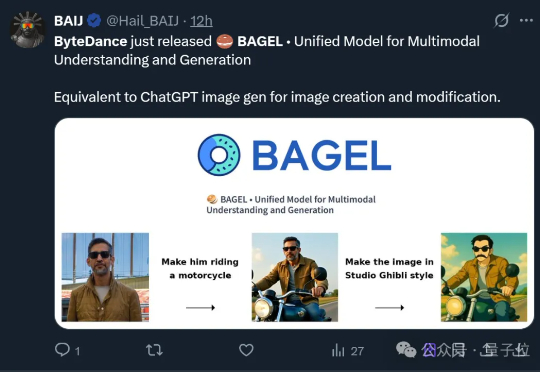
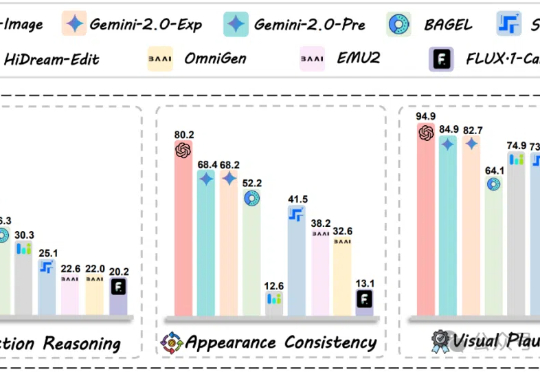
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。