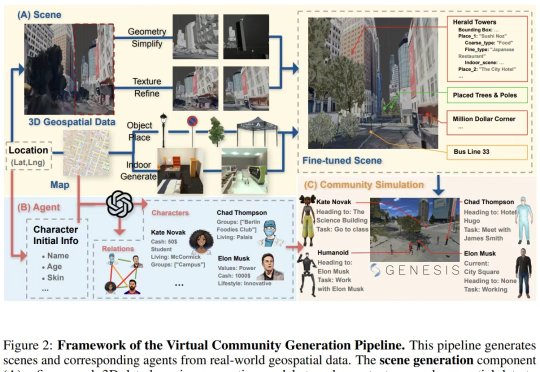
世界模型版《模拟人生》:AI虚拟小人街头演讲拉票,GPT-4o选举获胜
世界模型版《模拟人生》:AI虚拟小人街头演讲拉票,GPT-4o选举获胜一个真实世界模拟器。
来自主题: AI技术研报
8569 点击 2025-06-21 19:25
 搜索
搜索
一个真实世界模拟器。
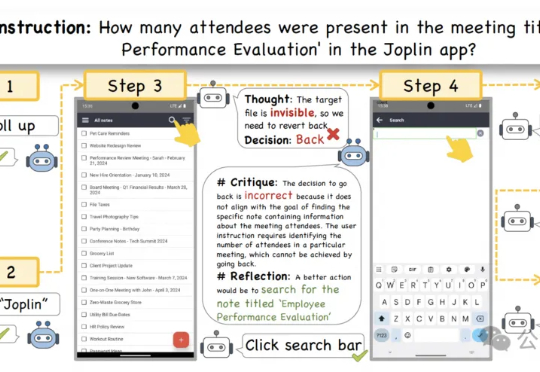
GUI智能体总是出错, 甚至是不可逆的错误。 即使是像GPT-4o这样的顶级多模态大模型,也会因为缺乏常识而在执行GUI任务时犯错。在它即将执行错误决策时,需要有人提醒它出错了。

NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。

Landbase 践行着Daniel Saks (萨克斯)称之为"氛围感市场进入"的策略,利用 AI 实现营销触达自动化。本周该公司宣布完成 3000 万美元 A 轮融资,由 Sound Ventures 与现有投资者 Picus Capital 共同领投,8VC、A*和 Firstminute Capital 等既有投资方跟投。

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
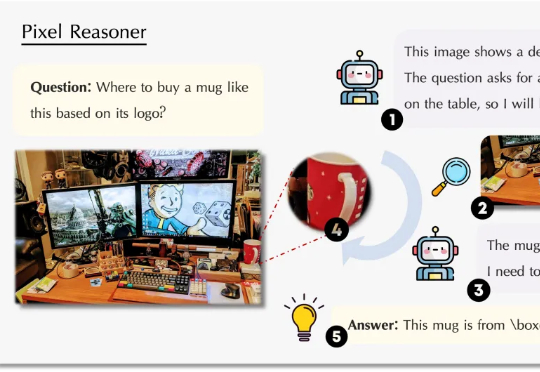
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。

前天,生财有术的老板亦仁发布了一条「超级标」(至少价值千万以上的现象级行业机会): 随着GPT-4o图像革命而来的,是无数的创业机会。

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。