
马斯克买了新厂房上GPU,2GW供电规模,“巨硬”更更硬了
马斯克买了新厂房上GPU,2GW供电规模,“巨硬”更更硬了马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。
来自主题: AI资讯
11674 点击 2025-12-31 15:12
 搜索
搜索
马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。

近日,刚刚 IPO 的国产 GPU 公司沐曦股份,完成了自上市后的首个重大技术发布。
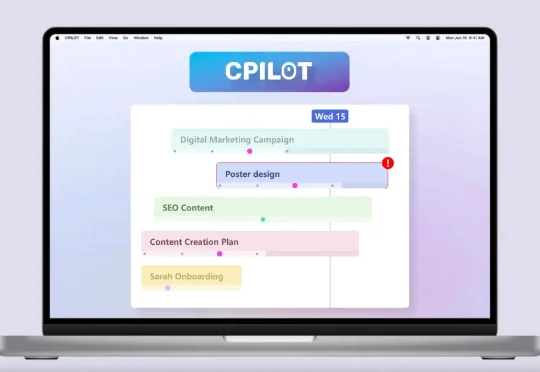
。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理
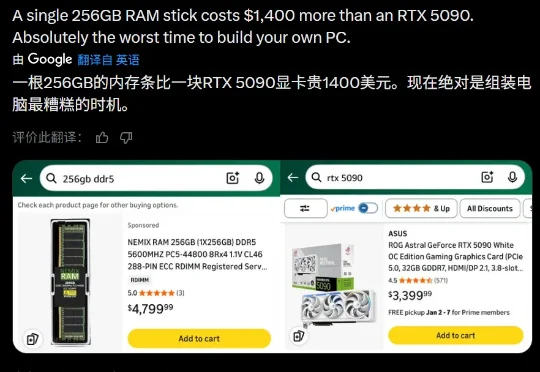
英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。

在生成式AI(GenAI)的推动下,2025年标志着行业从“震撼期”正式步入“深水区”。这并非资本的泡沫,而是计算范式从CPU向GPU的根本性迁移——数据中心正进化为实时生产智能的“AI工厂”。相比于模型参数的单纯竞赛,AI应用带来的“任务执行”能力与直观体验,让人切身感受到从“信息检索”向“智能生成”的范式跃迁。

刚刚,彼得·蒂尔一句话捅破天花板:AI芯片最终不会稀缺,将沦为白菜价。当AMD、ASIC、TPU、Trainium联手围剿,英伟达的暴利时代正在倒计时。

除了英特尔和AMD,现在我们终于可以选择国产笔记本电脑显卡了!这款显卡的背后,饱含着中国工程师们日夜攻坚的汗水与泪水。

从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。

这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
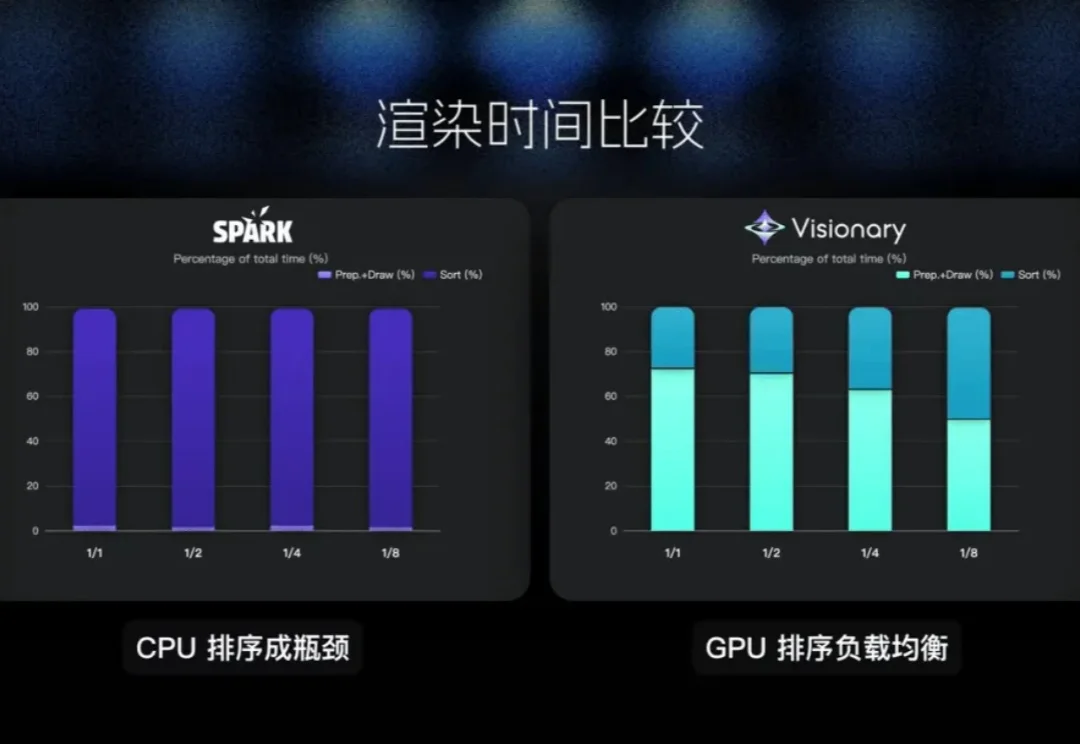
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。