
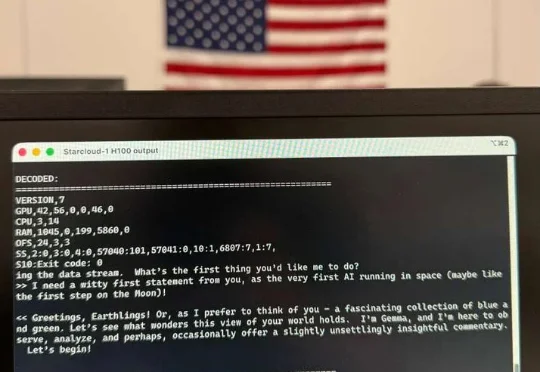
全球首个太空AI诞生,H100在轨炼出!马斯克爆赞
全球首个太空AI诞生,H100在轨炼出!马斯克爆赞见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。
来自主题: AI资讯
10148 点击 2025-12-11 16:27
见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。
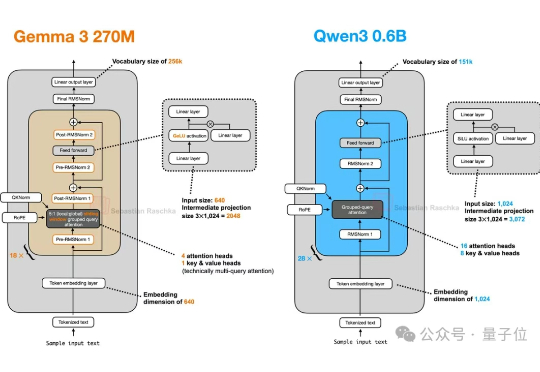
谷歌开源Gemma 3 270M闪亮登场!只需几分钟即可完成微调,指令遵循和文本结构化能力更是惊艳,性能超越Qwen 2.5同级模型。

Google双线出击!T5Gemma重燃encoder-decoder架构战火,性能暴涨12分;MedGemma坚守decoder-only路线,强攻医疗多模态,击穿闭源壁垒。Gemma体系完成「架构+落地」双重进化,打响Google开源反击战。
今天是 xAI 的大日子,伊隆・马斯克早早就宣布了会在今天发布 Grok 4 大模型,AI 社区的眼球也已经向其聚拢,就等着看他的直播(等了挺久)。当然,考虑到 Grok 这些天的「失控」表现,自然也有不少人是在等着看笑话。
移动端侧模型迎来“新王”。

当地时间 6 月 26 日,在上个月的 Google I/O 上首次亮相预览后,谷歌如今正式发布了 Gemma 3n 完整版,可以直接在本地硬件上运行。
本周五凌晨,谷歌正式发布、开源了全新端侧多模态大模型 Gemma 3n。谷歌表示,Gemma 3n 代表了设备端 AI 的重大进步,它为手机、平板、笔记本电脑等端侧设备带来了强大的多模式功能,其性能去年还只能在云端先进模型上才能体验。

MedGemma是谷歌 “健康人工智能开发者基础”(Health AI Developer Foundations)计划的核心项目。基于 Gemma 3 架构, MedGemma提供多模态和纯文本两种模型变体,旨在降低医疗 AI 开发门槛。

谷歌 Gemma 3 上线刚刚过去一个月,现在又出新版本了。
神奇!人类和海豚真的能实现跨物种交流了?!