强化学习带来的改进只是「噪音」?最新研究预警:冷静看待推理模型的进展
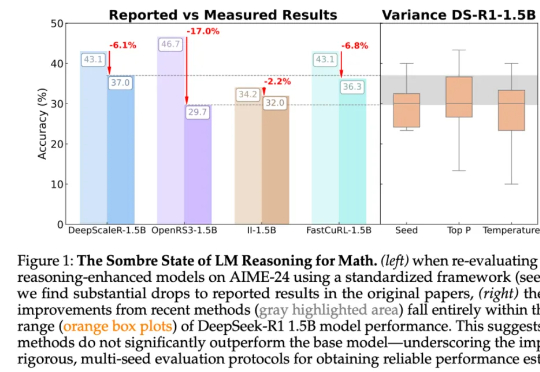
强化学习带来的改进只是「噪音」?最新研究预警:冷静看待推理模型的进展尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」
来自主题: AI技术研报
6533 点击 2025-04-13 15:59