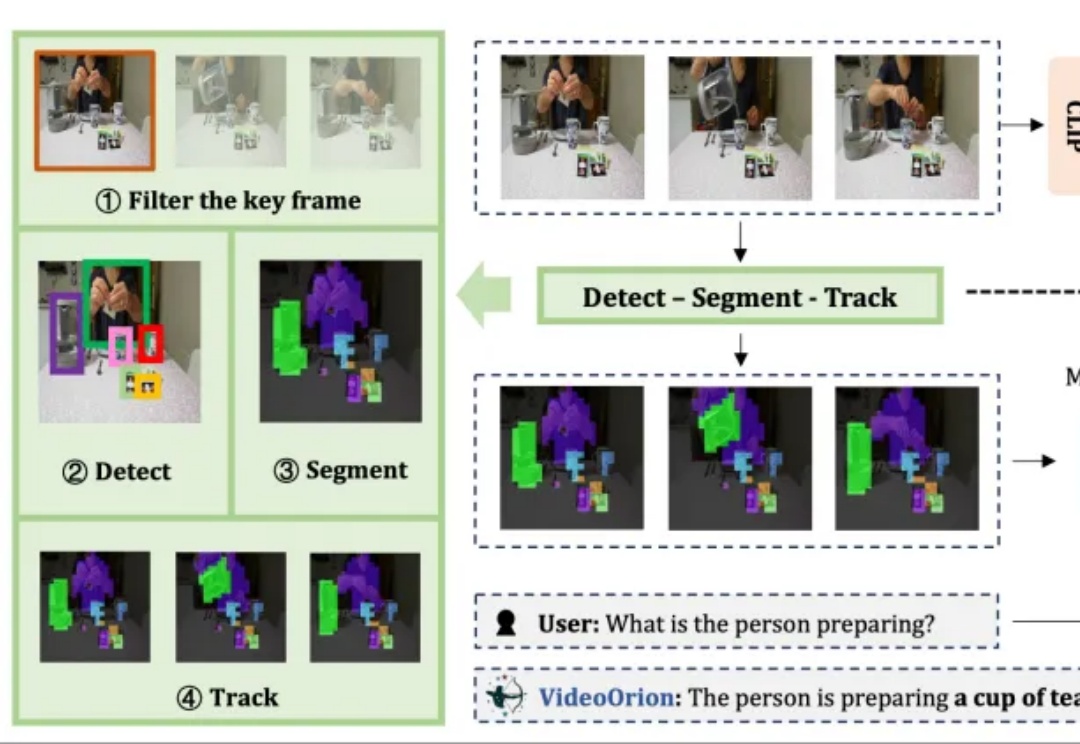
视频大模型新基元:用Object Tokens重塑细节感知与指代理解
视频大模型新基元:用Object Tokens重塑细节感知与指代理解被顶会ICCV 2025以554高分接收的视频理解框架来了!
来自主题: AI技术研报
8564 点击 2025-11-28 09:24
 搜索
搜索
被顶会ICCV 2025以554高分接收的视频理解框架来了!
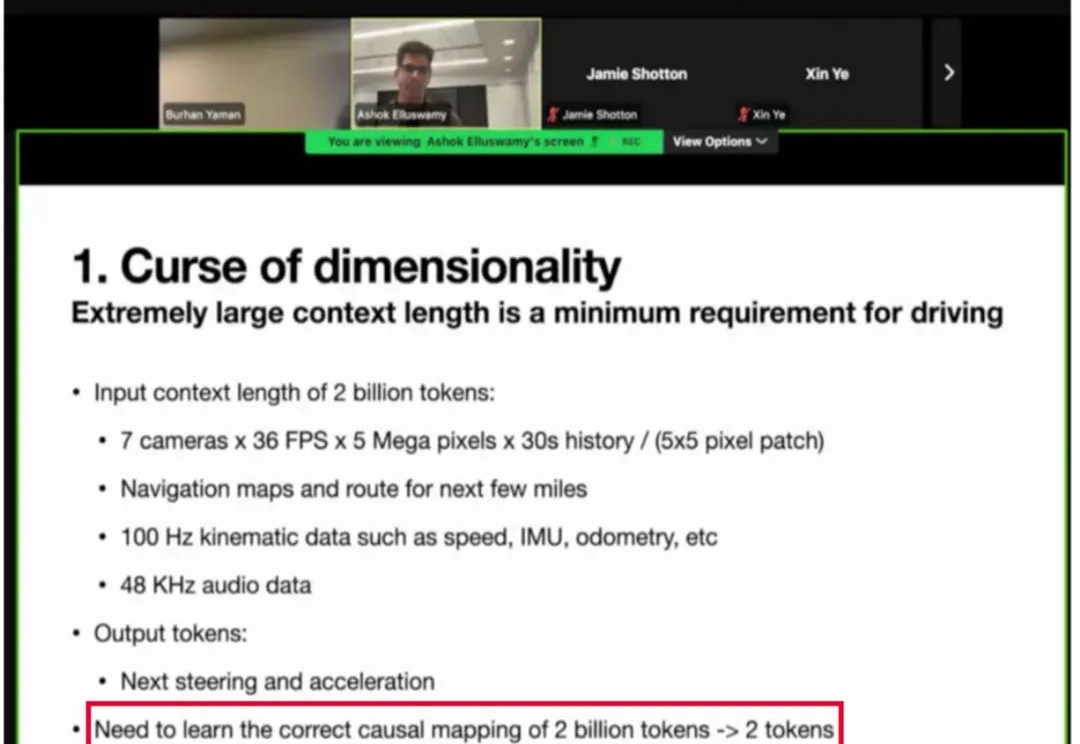
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。
你是否曾为搭建具身仿真环境耗费数周学习却效果寥寥? 是否因人工采集海量交互数据需要高昂成本而望而却步? 又是否因找不到足够丰富真实的开放场景让你的智能体难以施展拳脚?

智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。
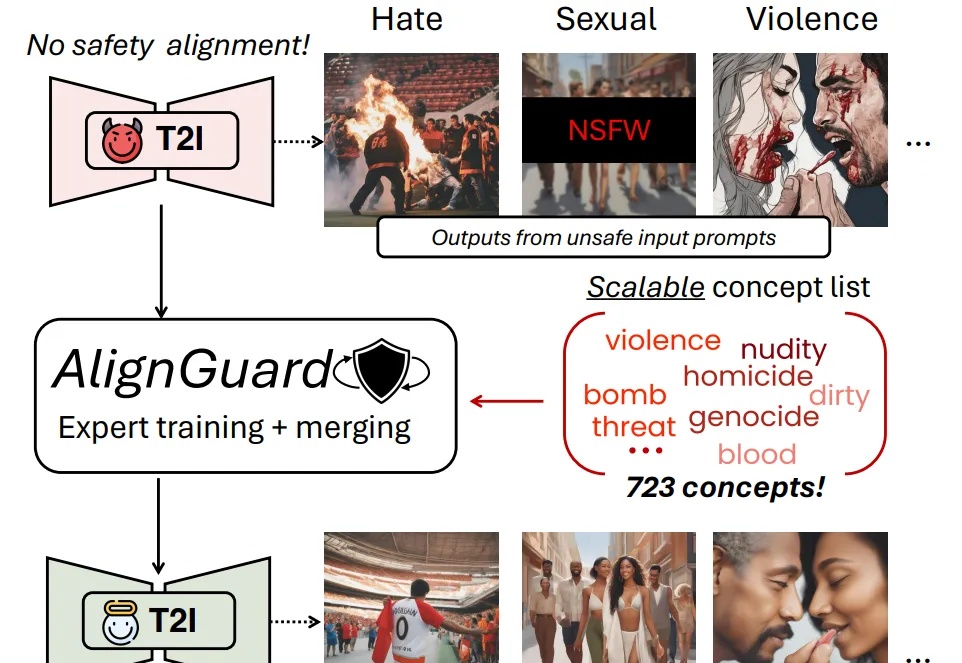
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。

3D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。

羡慕现在搞AI的大家。去一下学术顶会,工作机会现场就来了。是的,大厂AI招聘的风,已经吹到ICCV 2025。而今年的ICCV一逛,我们还真看到了点不一样的花活——顶会直聘。

ICCV最佳论文新鲜出炉了!今年,CMU团队满载而归,斩获最佳论文奖和最佳论文提名。同时,何恺明团队论文,RBG大神提出的Fast R-CNN,十年后斩获Helmholtz Prize,实至名归。

AI 会写字吗?在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!