ICLR 2026 | Rebuttal 是一场「带着镣铐的舞蹈」?港科 RebuttalAgent 用心智理论「读懂」审稿人
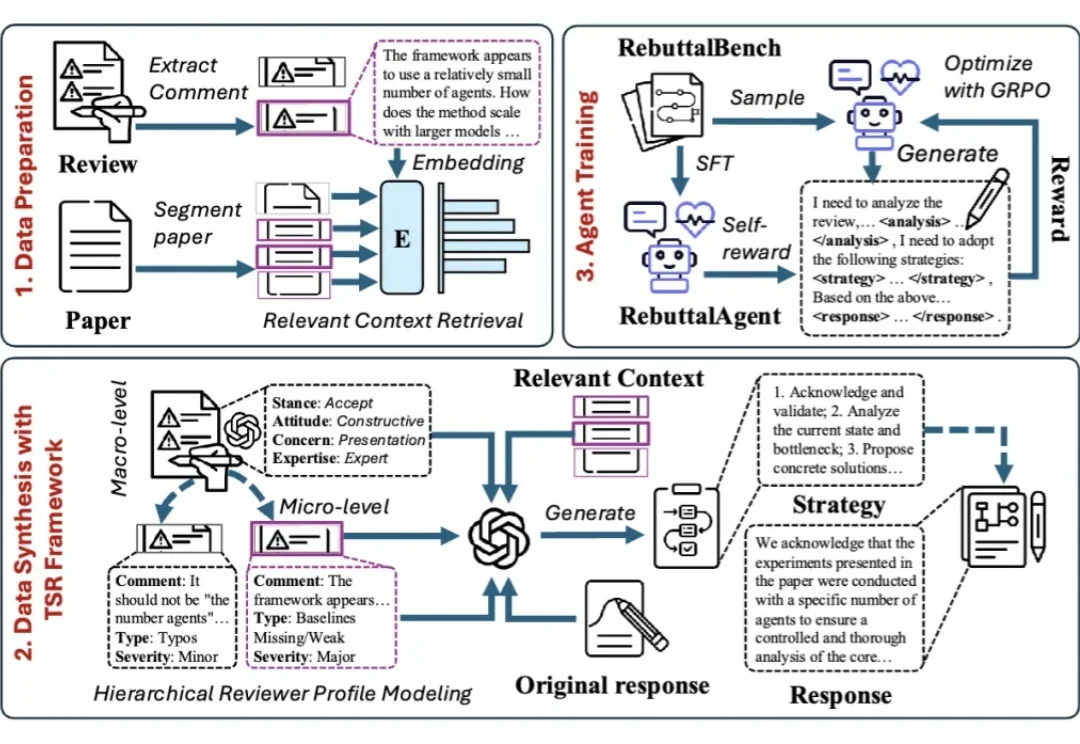
ICLR 2026 | Rebuttal 是一场「带着镣铐的舞蹈」?港科 RebuttalAgent 用心智理论「读懂」审稿人面对同行评审,许多作者都有过这样的经历:明明回答了审稿人的每一个问题,态度也足够谦卑,为什么最终还是没能打动对方?
来自主题: AI技术研报
8159 点击 2026-02-04 16:30
 搜索
搜索
面对同行评审,许多作者都有过这样的经历:明明回答了审稿人的每一个问题,态度也足够谦卑,为什么最终还是没能打动对方?

为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?

如果论文是AI写给AI看的,那人类还剩下什么?

ICLR 2026 的 Rebuttal 结束了。当 OpenReview 上的喧嚣散去,我们发现,作者与审稿人之间漫长的拉锯战,最终往往只剩下一个核心分歧:「这个想法,以前真的没人做过吗?」

史上首次,ICLR成立后设立机制设计相关Workshop,全球顶流学者众神云集!

两个月前,女演员 Tilly Norwood 遭遇了一场「网暴」。

这届 ICLR 的烦心事还没有结束。

21%的审稿意见竟全是AI生成的!「AI写,AI审」,ICLR裸奔事故从人肉搜索、金钱贿赂到全网吃瓜,这场闹剧撕开了学术圈最后的遮羞布。深度复盘这疯狂的61分钟,见证AI顶会史上最荒诞的一夜。

机器之心报道 编辑:+0、陈陈 最近,学术圈的大瓜莫过于 ICLR 评审大开盒事件了,只要在浏览器上输入某个网址,自行替换你要看的 paper ID 和审稿人编号,你就可以找到对应的审稿人身份。你甚至

ICLR 2026,居然有21%的评审是纯纯由AI生成的?!