学生3年投稿6次被拒,于是吴恩达亲手搓了个评审Agent
学生3年投稿6次被拒,于是吴恩达亲手搓了个评审Agent科研人不容易。3年投稿6次全被拒,每次等反馈要半年??机器学习大佬吴恩达听说这位学生的“水逆”遭遇后,亲手搓了个免费的AI论文评审智能体出来。通过在ICLR 2025审稿数据上训练系统,并在测试集中对比发现,该AI审稿系统与人类审稿的相关系数达0.42,和人与人审稿间的0.41相近甚至还高一点。
来自主题: AI资讯
9521 点击 2025-11-25 17:17
 搜索
搜索
科研人不容易。3年投稿6次全被拒,每次等反馈要半年??机器学习大佬吴恩达听说这位学生的“水逆”遭遇后,亲手搓了个免费的AI论文评审智能体出来。通过在ICLR 2025审稿数据上训练系统,并在测试集中对比发现,该AI审稿系统与人类审稿的相关系数达0.42,和人与人审稿间的0.41相近甚至还高一点。

面对泛滥成灾的AI生成论文与注水评审,AI顶会ICLR终于祭出「核威慑」:除了惩罚未主动披露滥用AI的论文作者外,用AI敷衍的评审者,自己的论文也将面临拒稿。

在号称「史上最严管控AI」的顶级会议ICLR 2026上,评审区却悄悄被大模型攻占。每五条审稿意见里,就有一条几乎全由AI一键生成。当作者怀疑评审是机器人写的、审稿人又怀疑论文是模型拼的,同行评审这台「科学秩序的发动机」,正一点点滑向一场没人承认、却无处不在的自动化实验。
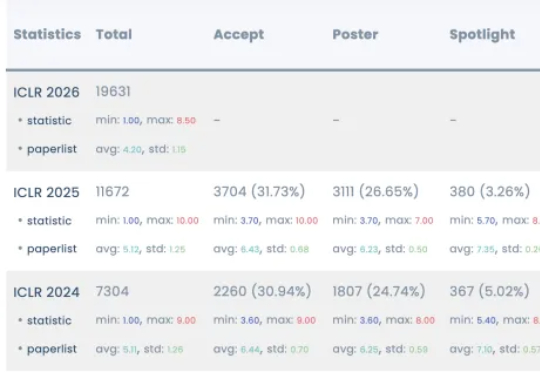
ICLR 2026评审结果震撼出炉:投稿量暴增至近2万篇,却迎来分数大滑坡,平均分从5.12跌至4.2。审稿人吐槽论文质量低下,甚至疑似AI生成,这场学术盛宴为何变味?
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。

2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
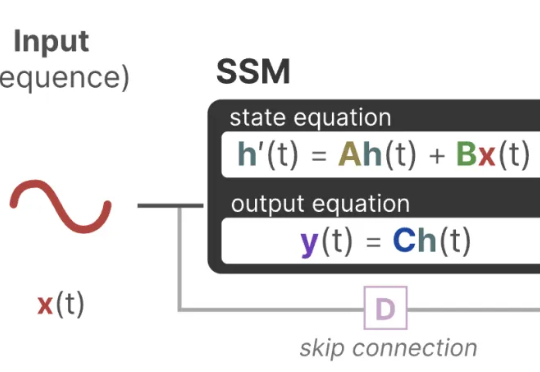
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。

在9月底的苏黎世电影节上,一位名叫Tilly Norwood的「女演员」亮相,引发媒体和网友热议。「她」由AI制作公司Particle6打造,是全球首批AI生成演员角色之一。Tilly的出现,意味着以Sora为代表的AI视频生成技术正加速渗透,并可能深刻改变影视行业。
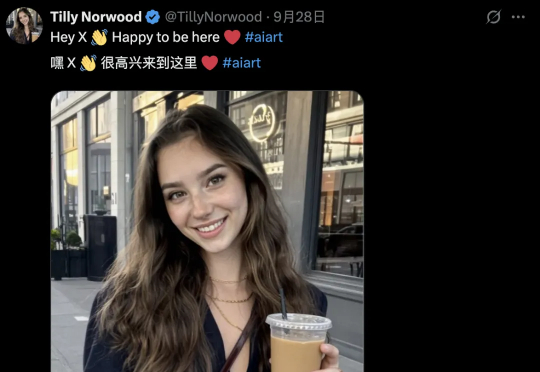
Tilly Norwood 有一张干净的脸孔,能演超英大片里的配角,也能出现在 BBC2 的喜剧小品里。但唯一的问题是:她不存在。她是英国公司 Particle6 Productions 用 AI 生成的「女演员」。从脸到声线、从履历到社交账号,全部都是虚拟构建。