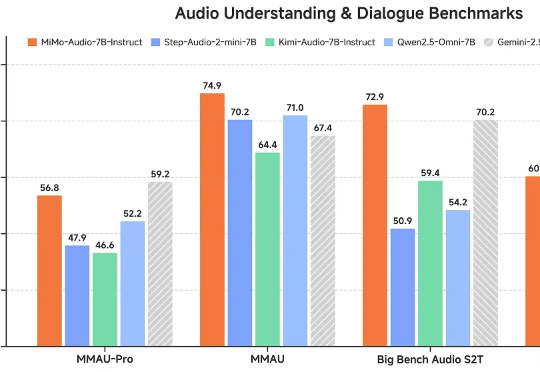
小米开源首个原生端到端语音大模型 Xiaomi-MiMo-Audio
小米开源首个原生端到端语音大模型 Xiaomi-MiMo-Audio这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
来自主题: AI资讯
10373 点击 2025-09-21 19:22
 搜索
搜索
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。

刚刚,又一个人工智能国际顶会为大模型「上了枷锁」。 ICLR 2025 已于今年 4 月落下了帷幕,最终接收了 11565 份投稿,录用率为 32.08%。
AI来了,一场悄无声息的「岗位绝种」来了。AI已深度渗透新闻采编、聚合与分发流程,从Perplexity豪赌345亿美元收购Chrome,到Particle打造全景式新闻摘要,AI正重构信息入口与用户体验。记者岗位面临「寂静灭绝」,57%的人认为会被取代。
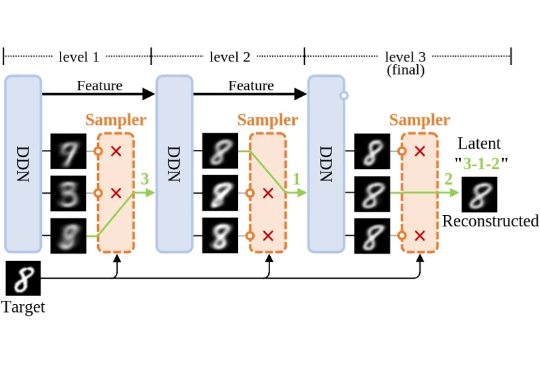
本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
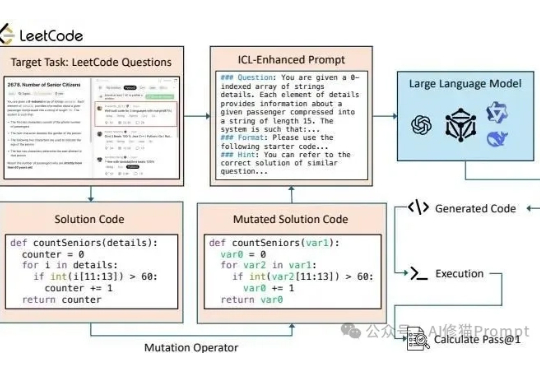
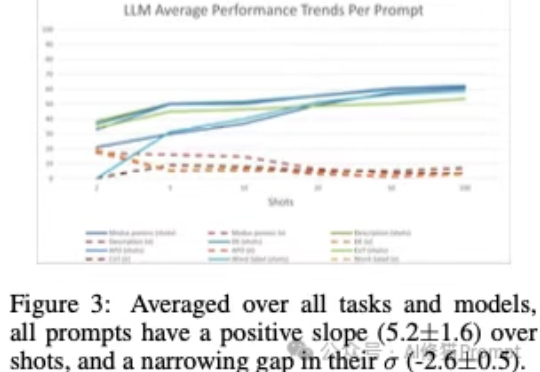
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
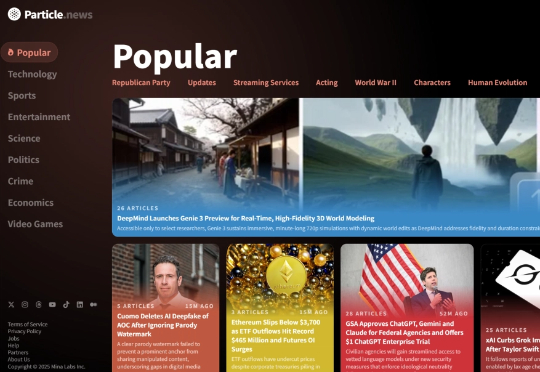
厌倦了在Google News、X等平台间切换导致的信息茧房,我发现Particle News通过AI将碎片化新闻整合为“故事拼盘”,并加入多视角分析、即时问答和政治光谱可视化功能,有望打破信息茧房束缚。
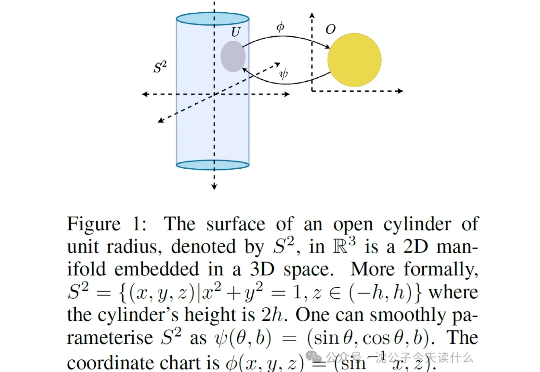
一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。
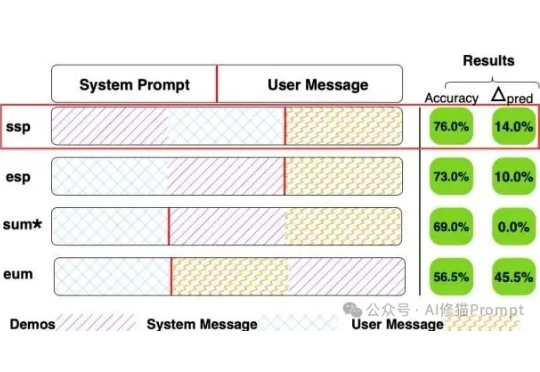
上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?
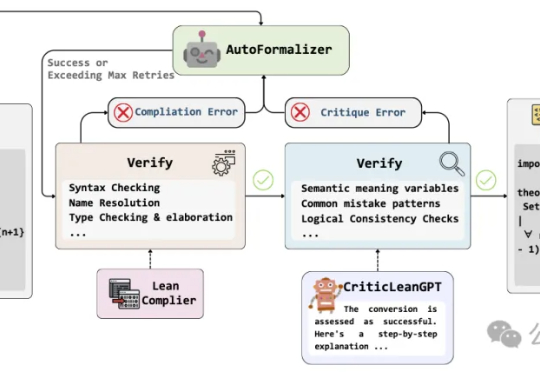
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。