深度|Karpathy为何突然加入Anthropic,只能当Dario的「-2」?
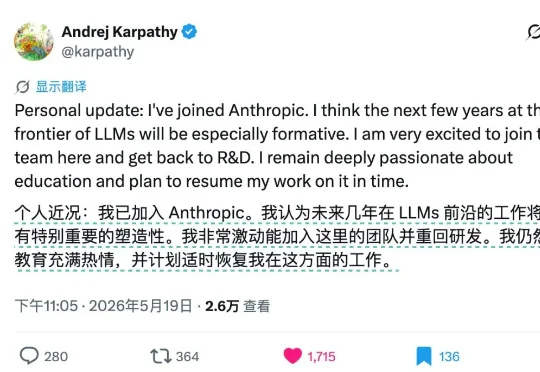
深度|Karpathy为何突然加入Anthropic,只能当Dario的「-2」?5 月 19 日,OpenAI 联合创始人、「Vibe Coding」之父 Andrej Karpathy 宣布加入 Anthropic 预训练团队。他将组建新团队,用 Claude 加速预训练研究。一个做过Hinton和李飞飞学生、奥特曼同事、马斯克直属下属的人,为什么甘愿做 Dario Amodei 的「-2」?Anthropic 又为什么非要招他?
来自主题: AI资讯
10413 点击 2026-05-20 10:14