
Meta陷入恐慌?内部爆料:在疯狂分析复制DeepSeek,高预算难以解释
Meta陷入恐慌?内部爆料:在疯狂分析复制DeepSeek,高预算难以解释「工程师正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。」DeepSeek 开源大模型的阳谋,切切实实震撼着美国 AI 公司。最先陷入恐慌的,似乎是同样推崇开源的 Meta。
来自主题: AI资讯
8490 点击 2025-01-24 10:59
 搜索
搜索
「工程师正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。」DeepSeek 开源大模型的阳谋,切切实实震撼着美国 AI 公司。最先陷入恐慌的,似乎是同样推崇开源的 Meta。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。
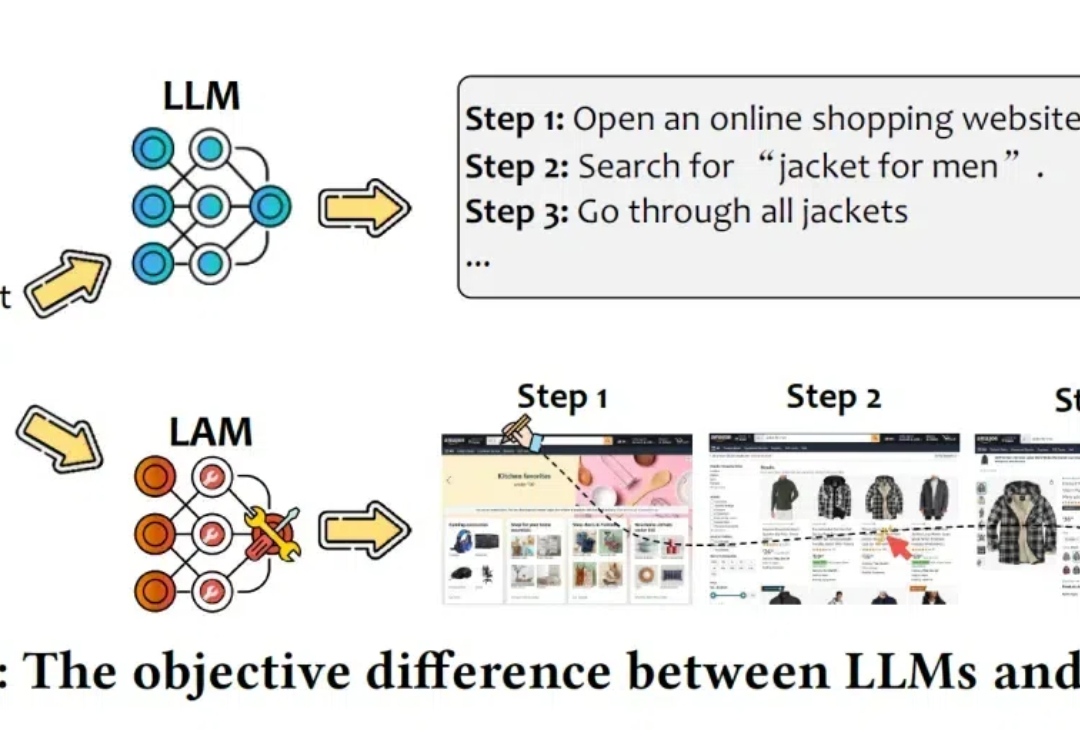
AI大模型正从仅会聊天的LLM进化为能够执行任务的大型行动模型LAM。它不仅能理解用户的指令,还能在软件环境中自主执行任务。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。

DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
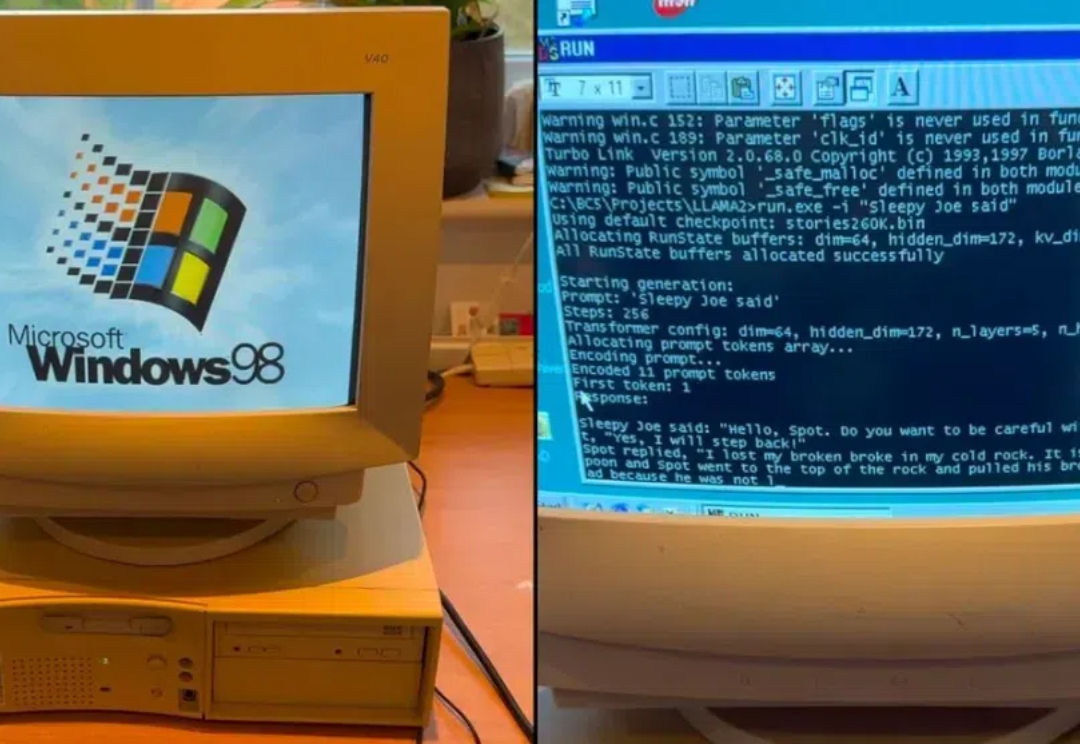
让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。

OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。
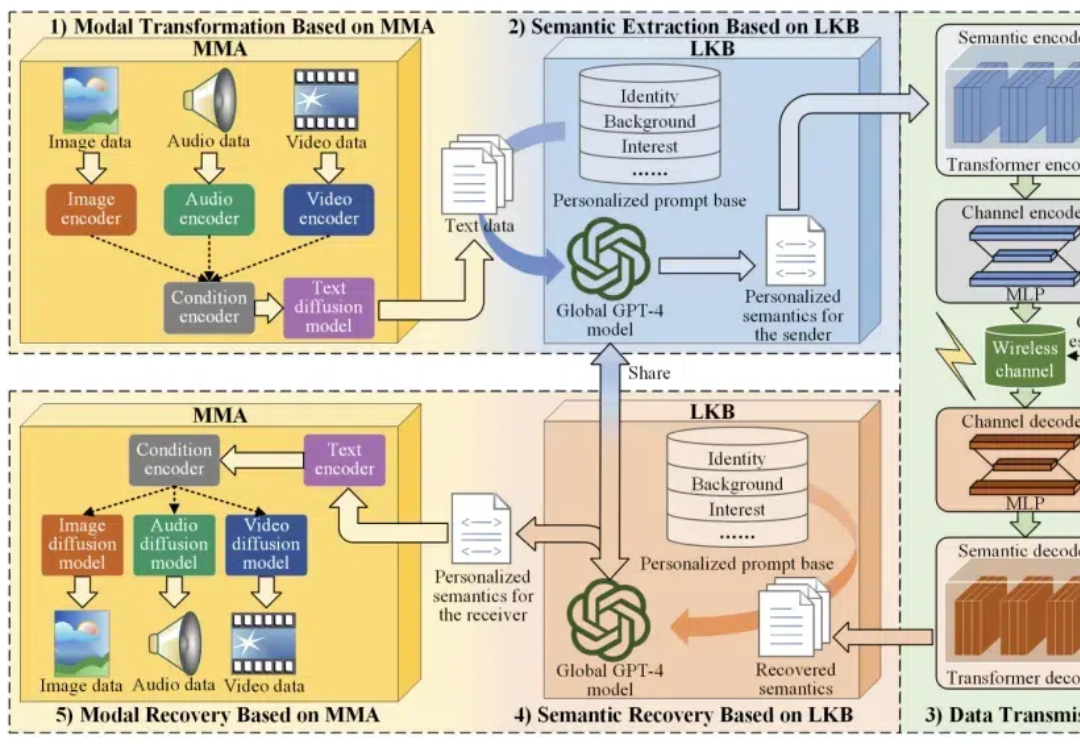
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。