
人形机器人的真机强化学习! ICLR 2026 通研院提出人形机器人预训练与真机微调新范式
人形机器人的真机强化学习! ICLR 2026 通研院提出人形机器人预训练与真机微调新范式目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
来自主题: AI技术研报
10853 点击 2026-02-08 11:56
 搜索
搜索
目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
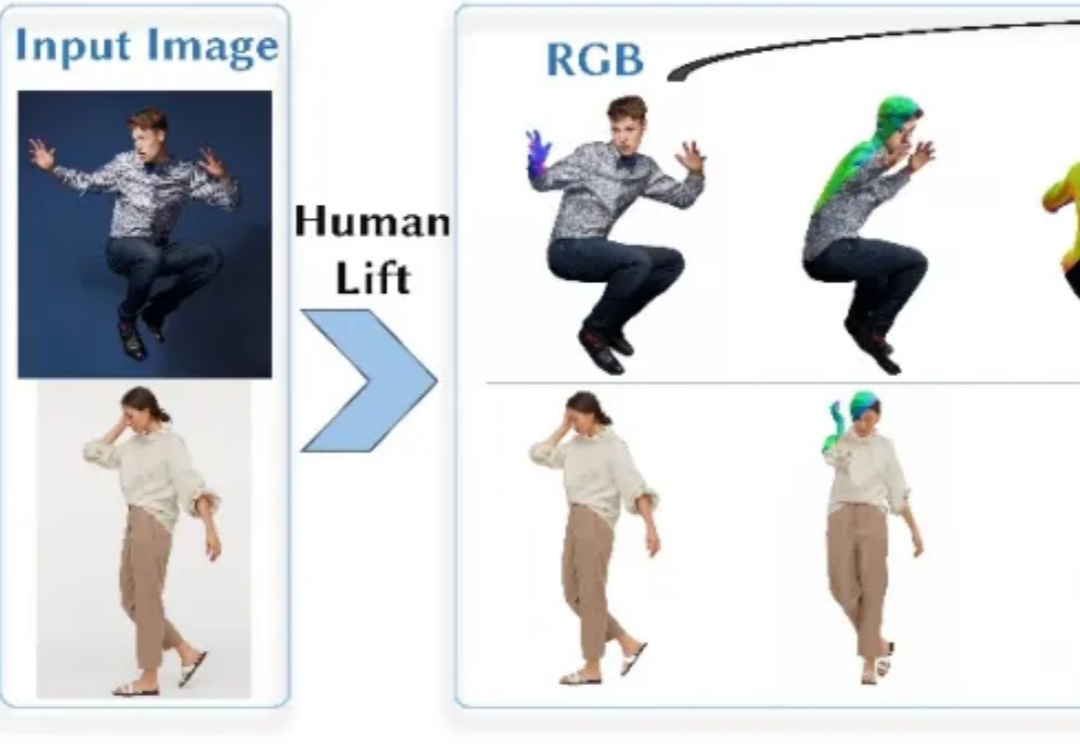
创建具有高度真实感的三维数字人,在三维影视制作、游戏开发以及虚拟/增强现实(VR/AR)等多个领域均有着广泛且重要的应用。
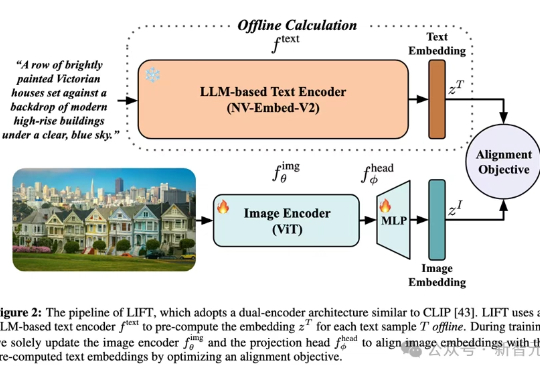
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。
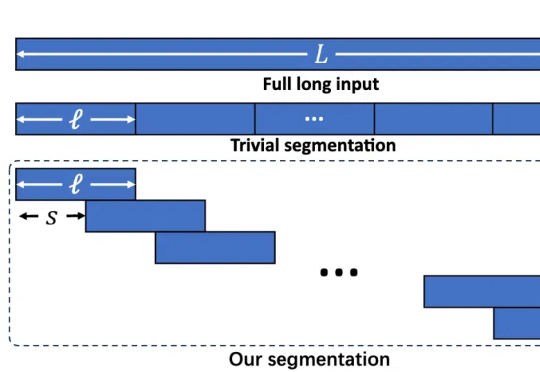
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。
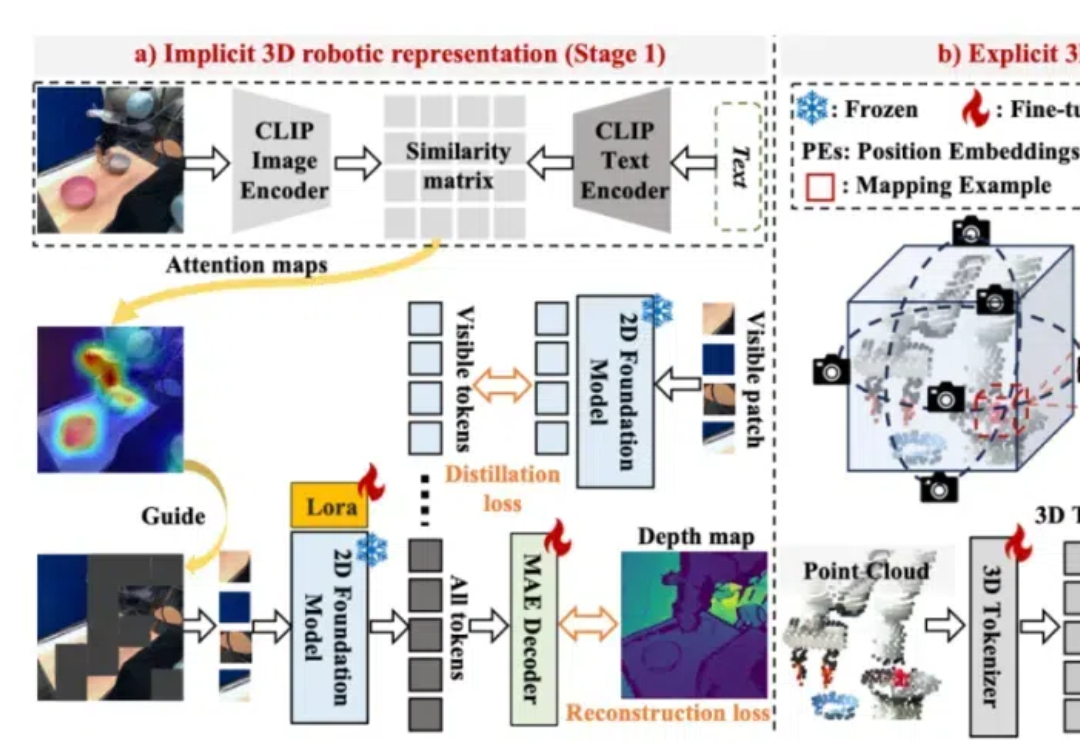
为了构建鲁棒的 3D 机器人操纵大模型,Lift3D 系统性地增强 2D 大规模预训练模型的隐式和显式 3D 机器人表示,并对点云数据直接编码进行 3D 模仿学习。Lift3D 在多个仿真环境和真实场景中实现了 SOTA 的操纵效果,并验证了该方法的泛化性和可扩展性。