
「大模型+强化学习」最新综述!港中文深圳130余篇论文:详解四条主流技术路线
「大模型+强化学习」最新综述!港中文深圳130余篇论文:详解四条主流技术路线大语言模型(LLM),通过在海量数据集上的训练,展现了超强的多任务学习、通用世界知识目标规划以及推理能力
来自主题: AI资讯
6625 点击 2024-04-11 22:45
 搜索
搜索
大语言模型(LLM),通过在海量数据集上的训练,展现了超强的多任务学习、通用世界知识目标规划以及推理能力

近日,来自佐治亚大学、新泽西理工学院、弗吉尼亚大学、维克森林大学、和腾讯 AI Lab 的研究者联合发布了解释性技术在大语言模型(LLM)上的可用性综述,提出了 「Usable XAI」 的概念,并探讨了 10 种在大模型时代提高 XAI 实际应用价值的策略。
一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」

大语言模型潜力被激发—— 无需训练大语言模型就能实现高精度时序预测,超越一切传统时序模型。
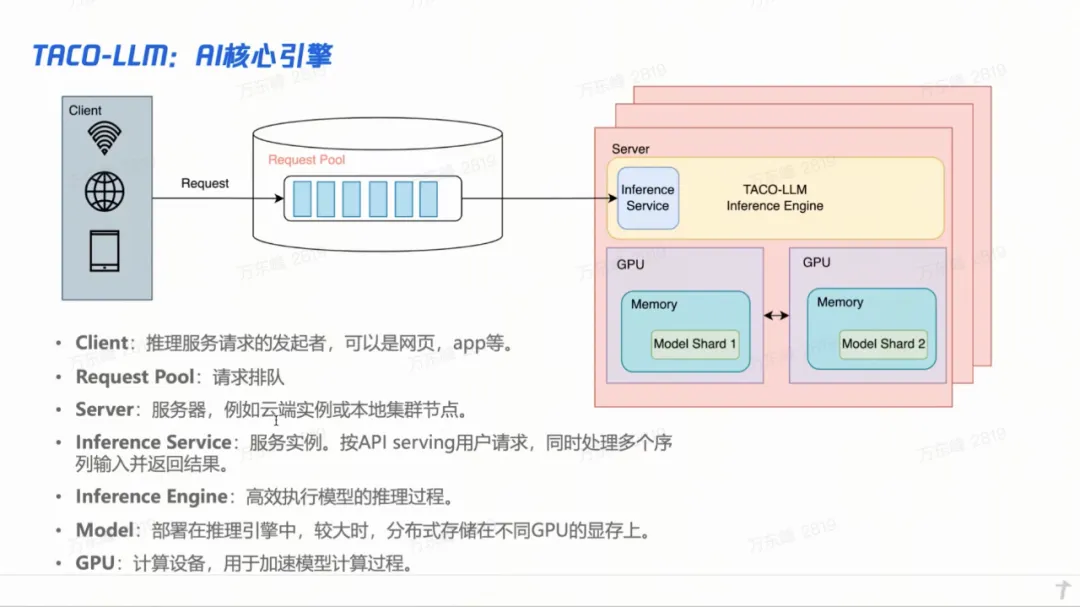
大模型在今年的落地,除了对用 AI 对已有业务进行改造和提效外,算力和推理的优化,可能是另外一项重要的实践了。这在腾讯的两个完全不同的业务上有着明显的体现。

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。

上个月,彭博社消息称苹果正在与 Google 进行谈判,希望将 Gemini 集成的 iPhone 当中,为 iPhone 的软件提供 AI 相关的新功能。把新系统的核心功能“外包”给第三方,这种做法非常不苹果。

大语言模型的「逆转诅咒」,被解开了。近日,来自Meta FAIR的研究人员推出了反向训练大法,让模型从反方向上学到了事实之间的逻辑,终于改进了这个困扰人们已久的问题。

距离AI「杀死」搜索引擎,到底还差几步?
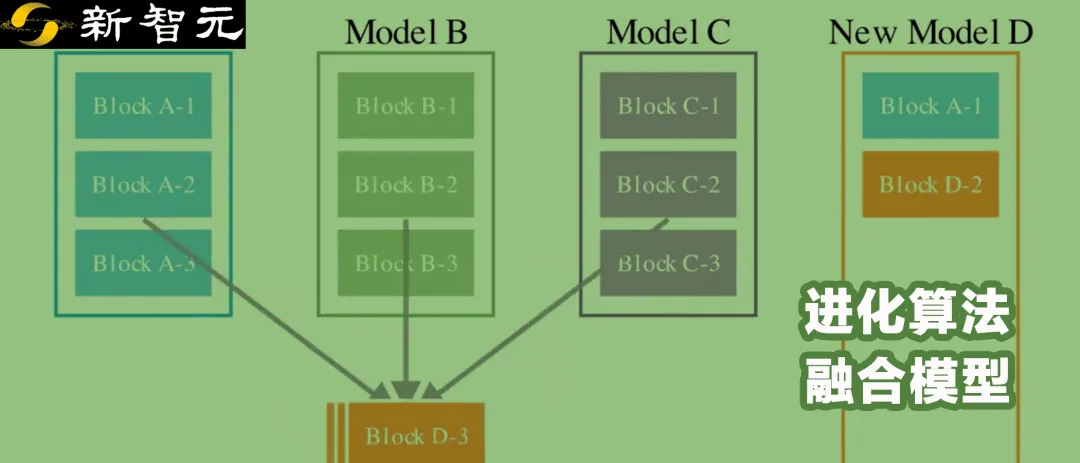
自动将不同开源模型进行组合,生成具有新能力的新模型,Sakana AI开发的新方法做到了!