基于文本AI的终结?Agent协作可直接「复制思维」,Token效率暴涨
基于文本AI的终结?Agent协作可直接「复制思维」,Token效率暴涨一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:
来自主题: AI技术研报
8063 点击 2025-12-06 11:08
 搜索
搜索
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:
这篇学术论长文由北京航空航天大学复杂关键软件环境全国重点实验室领衔。《From Code Foundation Models to Agents and Applications》一文是对过去几年代码智能领域的一次系统梳理:模型、任务、训练、智能体、安全与应用都被串联成了一条完整、连贯的技术链路。

这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。
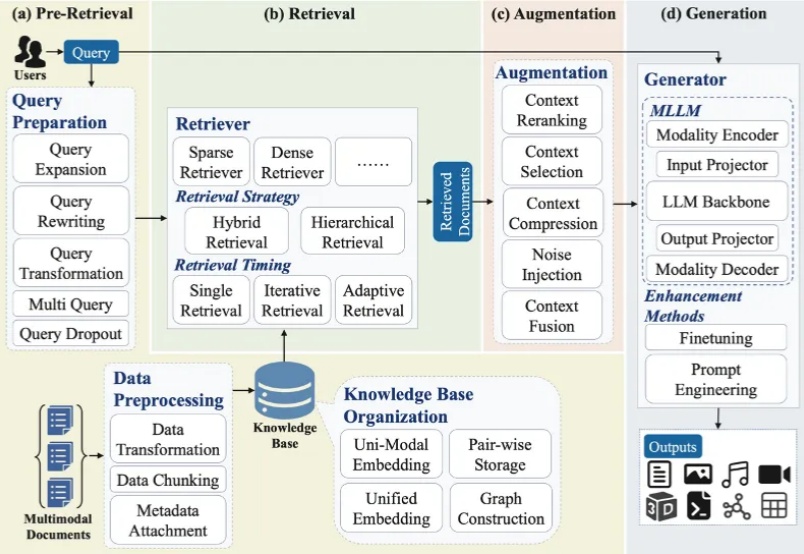
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。

人工智能在过去的十年中,以惊人的速度革新了信息处理和内容生成的方式。然而,无论是大语言模型(LLM)本体,还是基于检索增强生成(RAG)的系统,在实际应用中都暴露出了一个深层的局限性:缺乏跨越时间的、可演化的、个性化的“记忆”。它们擅长瞬时推理,却难以实现持续积累经验、反思历史、乃至真正像人一样成长的目标。