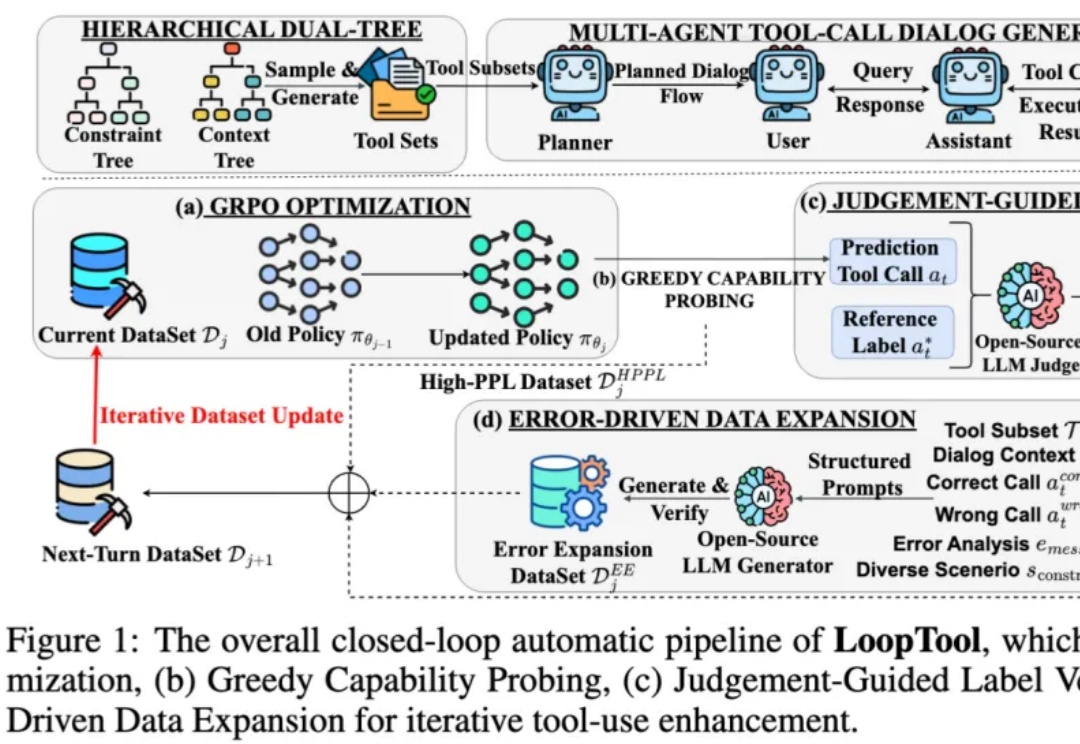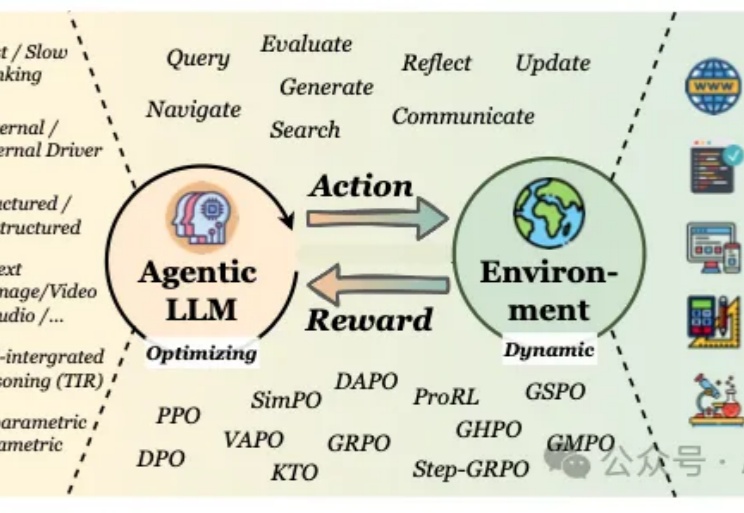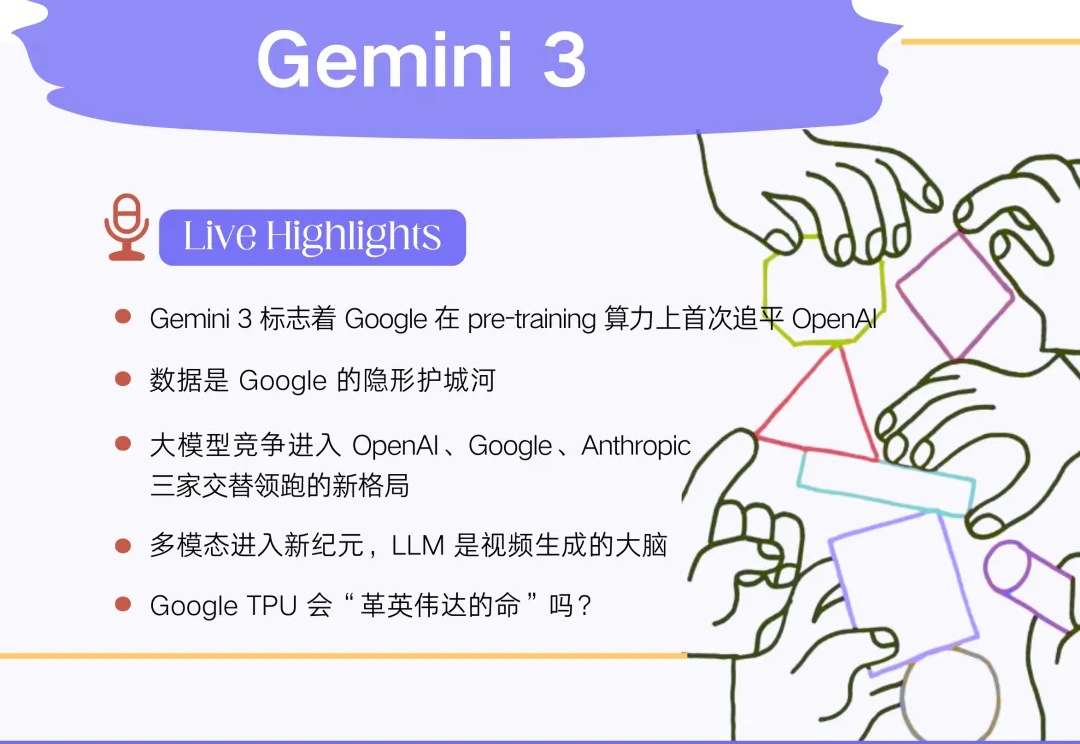
深度讨论 Gemini 3 :Google 王者回归,LLM 新一轮排位赛猜想|Best Ideas
深度讨论 Gemini 3 :Google 王者回归,LLM 新一轮排位赛猜想|Best Ideas最近两周的模型竞赛非常热闹:OpenAI 在 11 月 12 日发布 GPT-5.1,引入更强的推理深度与更高效的对话体验;Google 在 11 月 18 日发布 Gemini 3,全面强化多模态理解与复杂推理能力;Anthropic 在 11 月 24 日又发布了 Claude Opus 4.5,模型在专业文档处理、代码生成与长流程 agent 方面有显著提升。
来自主题: AI资讯
9401 点击 2025-11-28 09:27