成本仅0.3美元,耗时26分钟!CudaForge:颠覆性低成本CUDA优化框架
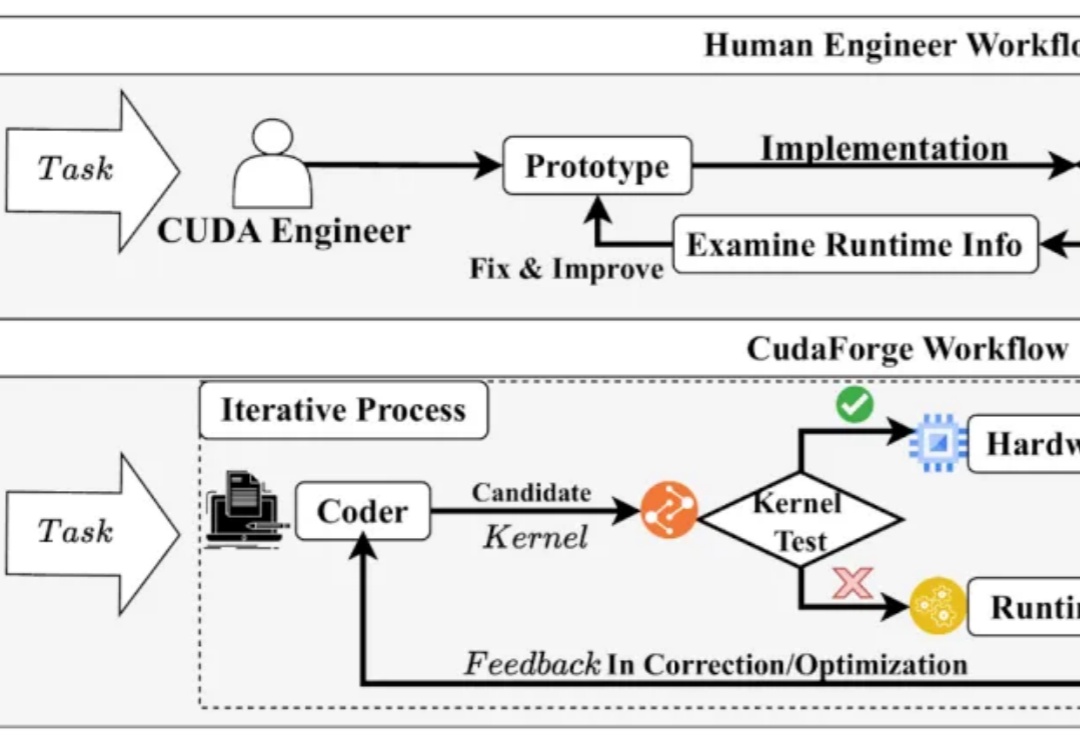
成本仅0.3美元,耗时26分钟!CudaForge:颠覆性低成本CUDA优化框架CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。
来自主题: AI技术研报
10716 点击 2025-11-18 10:06
 搜索
搜索
CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。
如何构建一个真正意义上的“自主代理”(Agent),而不是一个“带LLM的高级工作流”? 让钢铁侠中的“贾维斯”(J.A.R.V.I.S.)真正来到现实,不仅能对话,还能调动资源、控制机械、在复杂战局中自主执行多步任务。

图灵奖得主LeCun与Meta分道扬镳!LLM邪路一条,「世界模型才是」未来。
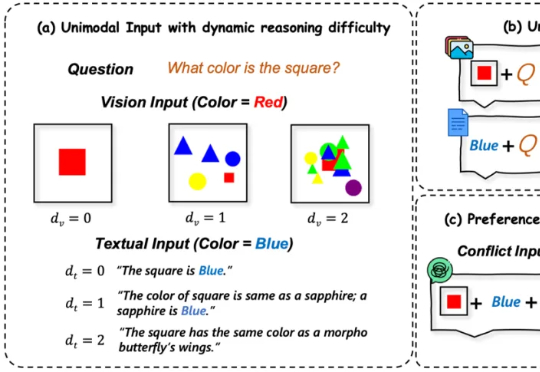
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)

谷歌在第三天发布了《上下文工程:会话与记忆》(Context Engineering: Sessions & Memory) 白皮书。文中开篇指出,LLM模型本身是无状态的 (stateless)。如果要构建有状态的(stateful)和个性化的 AI,关键在于上下文工程。
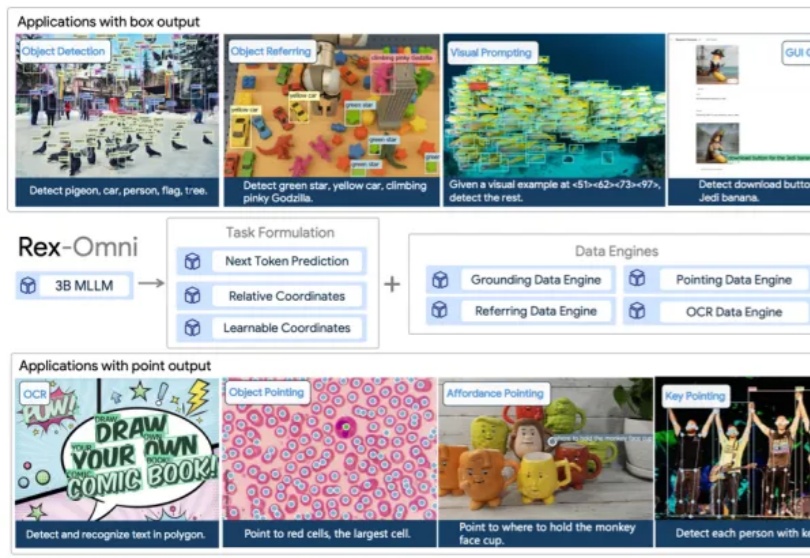
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
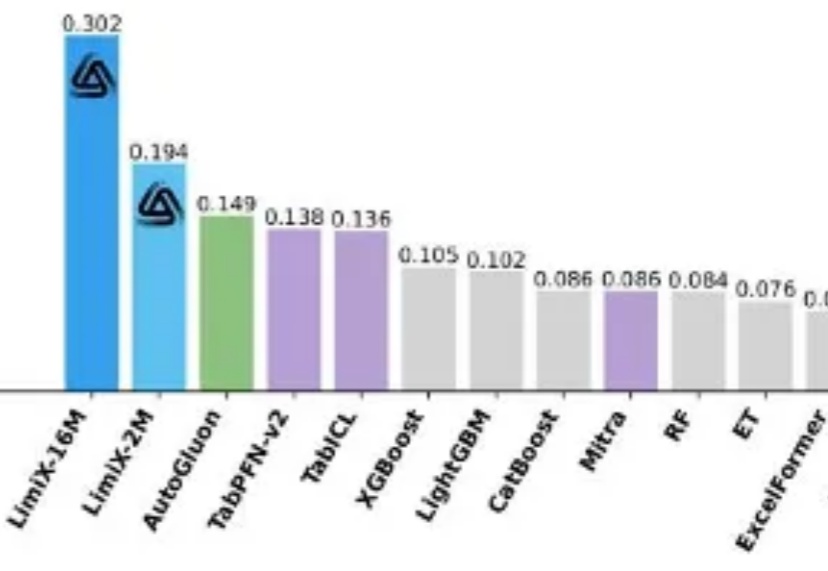
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
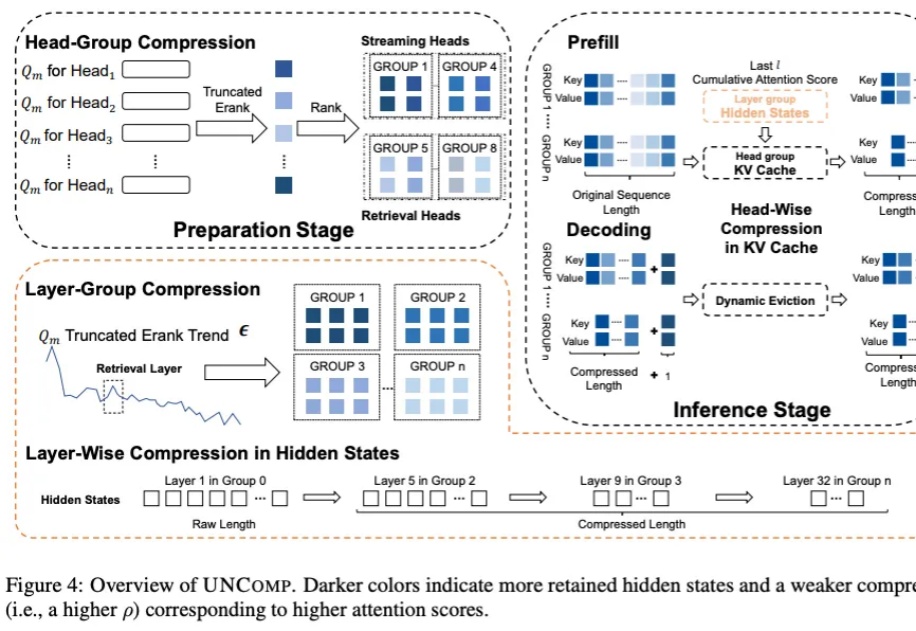
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
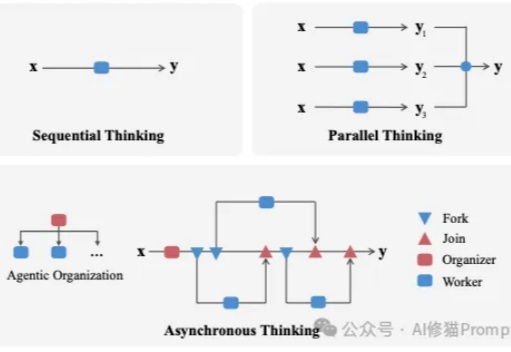
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。
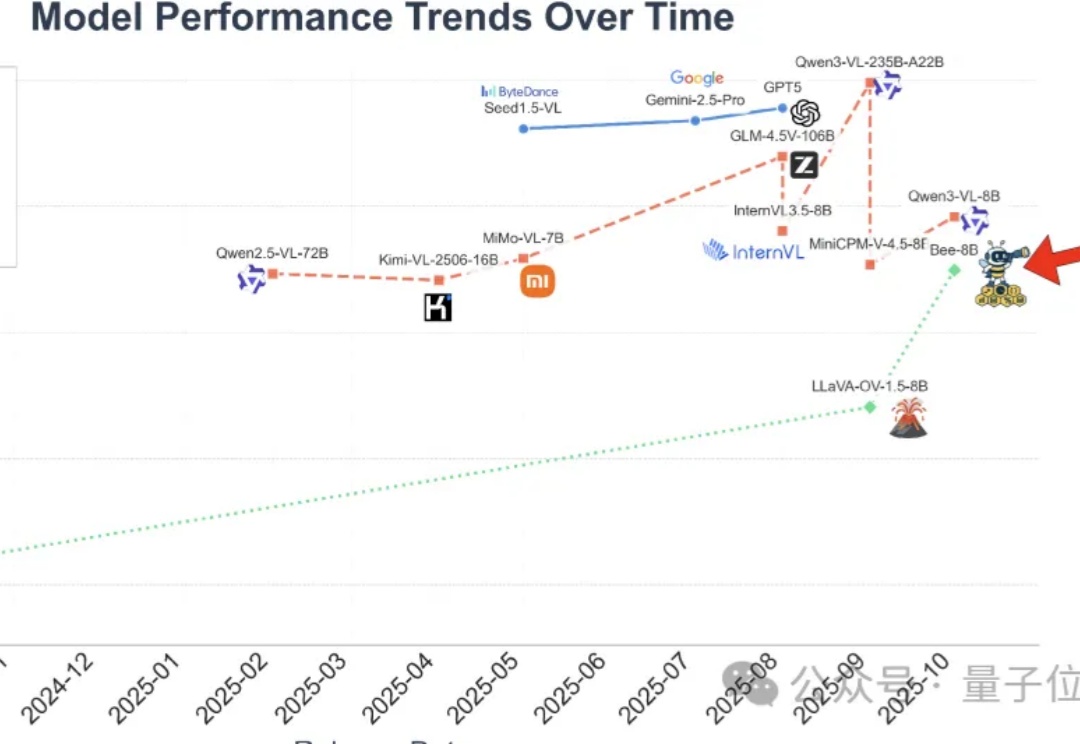
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。