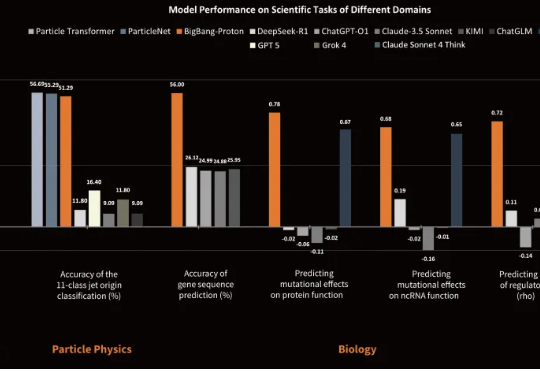
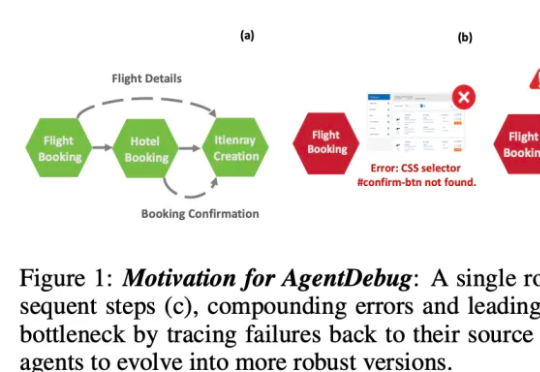
谷歌AlphaEvolve太香了,陶哲轩甚至发了篇论文,启发数学新构造
谷歌AlphaEvolve太香了,陶哲轩甚至发了篇论文,启发数学新构造著名数学家陶哲轩发论文了,除了陶大神,论文作者还包括 Google DeepMind 高级研究工程师 BOGDAN GEORGIEV 等人。论文展示了 AlphaEvolve 如何作为一种工具,自主发现新的数学构造,并推动人们对长期未解数学难题的理解。AlphaEvolve 是谷歌在今年 5 月发布的一项研究,一个由 LLMs 驱动的革命性进化编码智能体。
来自主题: AI资讯
9314 点击 2025-11-07 15:25