速递|Reddit创始人押注840万!Palabra攻克AI语音翻译“拟真实时”难题
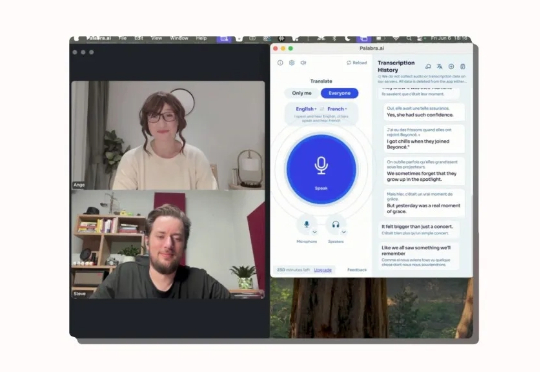
速递|Reddit创始人押注840万!Palabra攻克AI语音翻译“拟真实时”难题一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
来自主题: AI资讯
8980 点击 2025-08-16 15:43
 搜索
搜索
一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
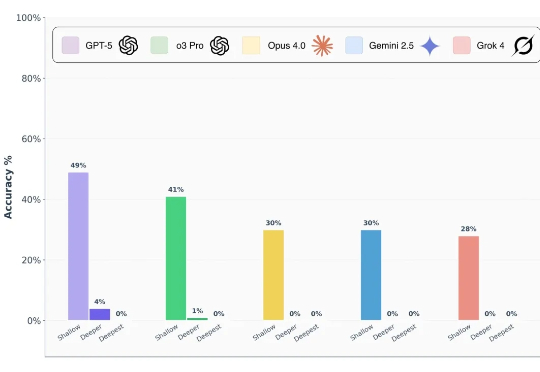
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

Anthropic 已收购 Humanloop 的联合创始人和大部分团队成员,该公司是一个专注于提示管理、LLM 评估和可观测性的平台,此举旨在强化其企业战略。
幻觉,作为AI圈家喻户晓的概念,这个词您可能已经听得耳朵起茧了。我们都知道它存在,也普遍接受了它似乎无法根除,是一个“老大难”问题。但正因如此,一个更危险的问题随之而来:当我们对幻觉的存在习以为常时,我们是否也开始对它背后的系统性风险变得麻木?我们是真的从第一性原理上理解了它,还是仅仅在用一个又一个的补丁(比如RAG)来被动地应对它?
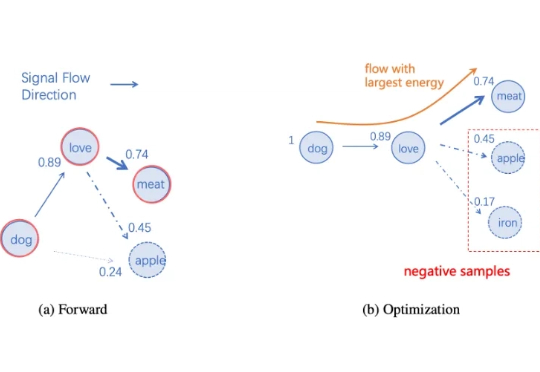
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
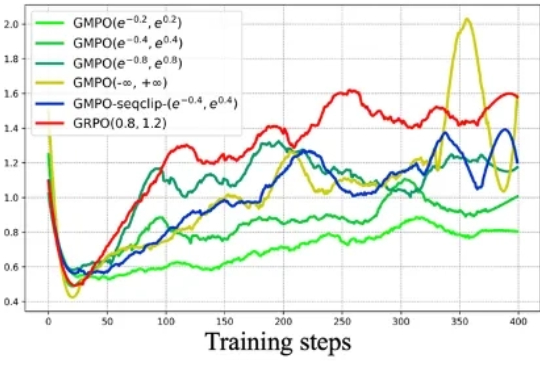
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
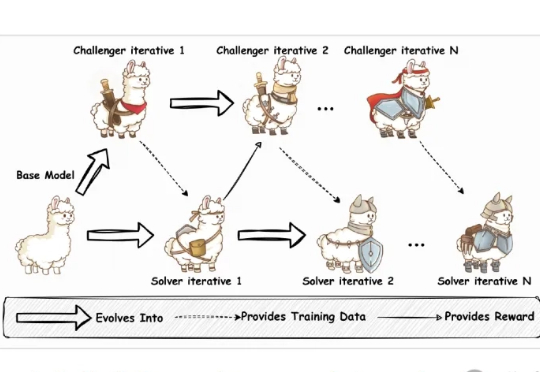
当前训练强大的大语言模型(LLM),就像是培养一个顶尖运动员,需要大量的、由专家(人类标注员)精心设计的训练计划和教材(高质量的标注数据)。
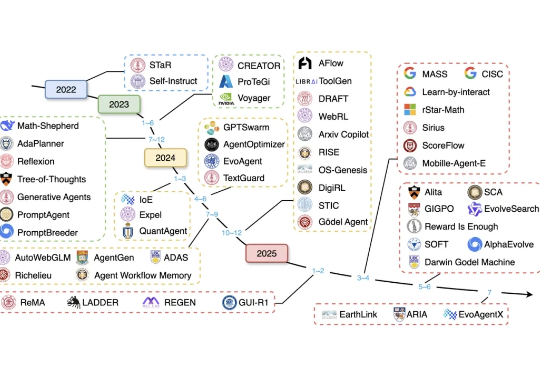
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。
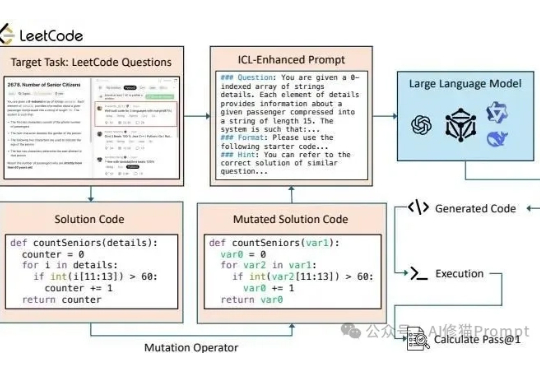
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。