
Attention Sink产生的起点?清华&美团首次揭秘MoE LLM中的超级专家机制
Attention Sink产生的起点?清华&美团首次揭秘MoE LLM中的超级专家机制稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
来自主题: AI技术研报
8433 点击 2025-08-12 11:07
 搜索
搜索
稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
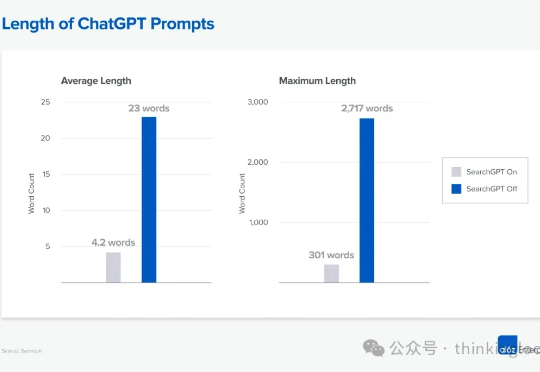
GEO/AEO,并不是一个全新的概念。简单说来,就是 AI 搜索和 LLM 时代的 SEO。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
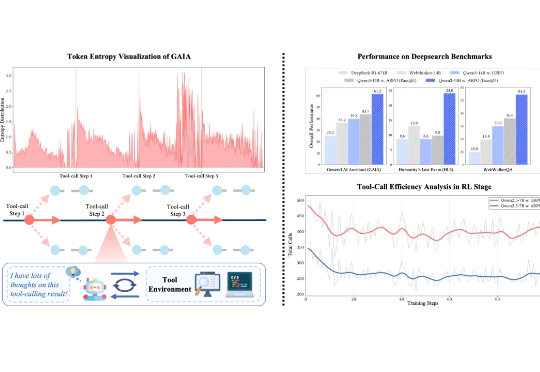
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
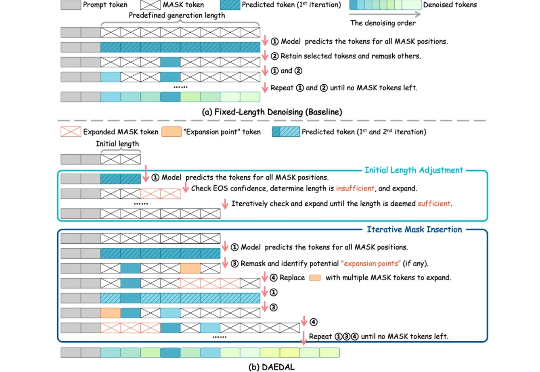
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。
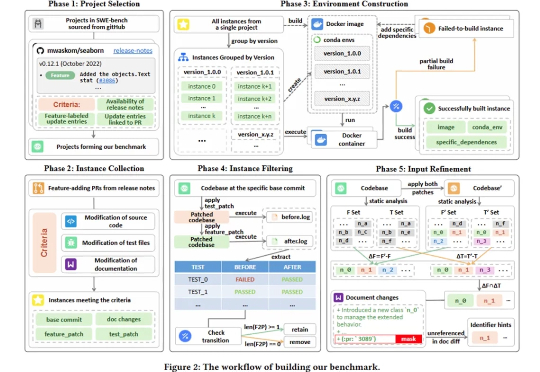
当前,大型语言模型(LLM)在软件工程领域的应用日新月异,尤其是在自动修复 Bug 方面,以 SWE-bench 为代表的基准测试展示了 AI 惊人的潜力。然而,软件开发远不止于修 Bug,功能开发与迭代才是日常工作的重头戏。
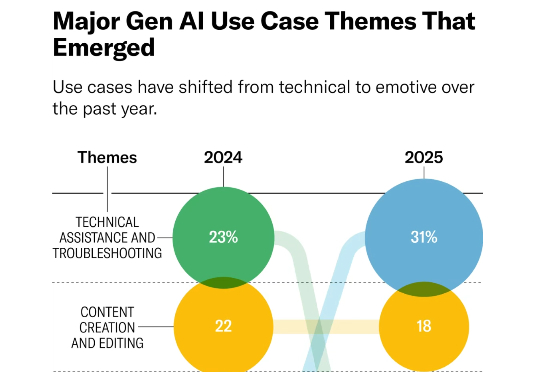
近一年来,围绕人工智能(AI)、生成式 AI(GenAI)和大语言模型(LLM)的炒作愈演愈烈,大众的兴趣翻了一番,针对 AI 的投资激增,各国政府也采取了更加明确的立场。根据一些人的说法,AI 与人类的未来息息相关。
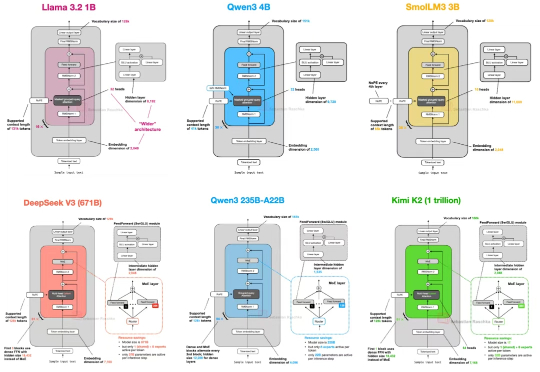
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
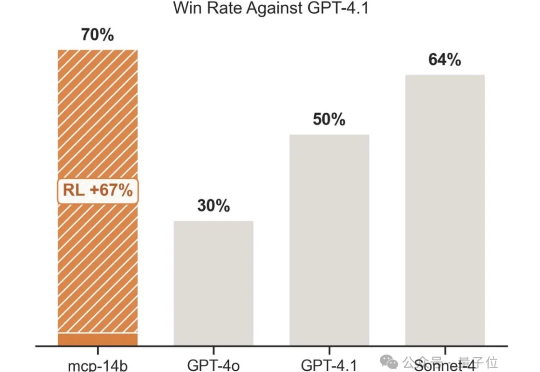
强化学习+任意一张牌,往往就是王炸。专注于LLM+RL的科技公司OpenPipe提出全新开源强化学习框架——MCP·RL。