人大高瓴-华为诺亚:大语言模型智能体记忆机制的系列研究
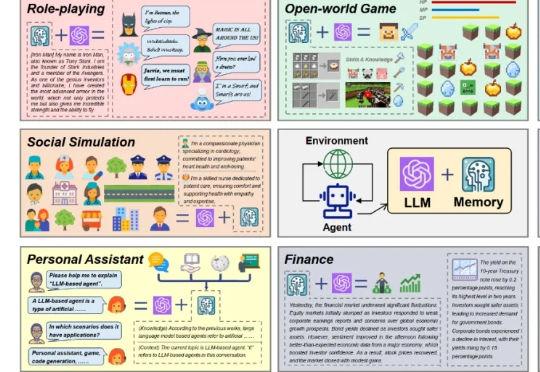
人大高瓴-华为诺亚:大语言模型智能体记忆机制的系列研究近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。
来自主题: AI技术研报
8085 点击 2025-08-07 17:03
 搜索
搜索
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。
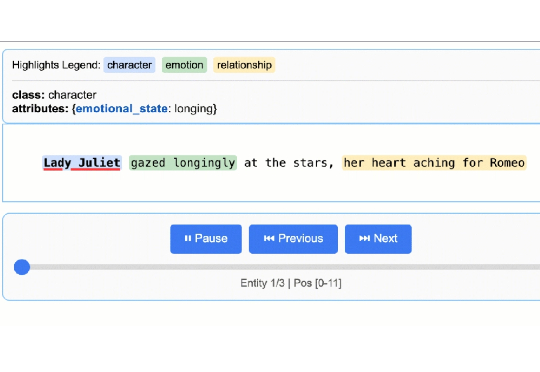
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
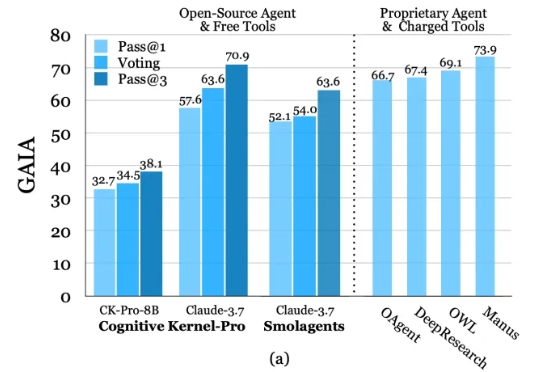
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
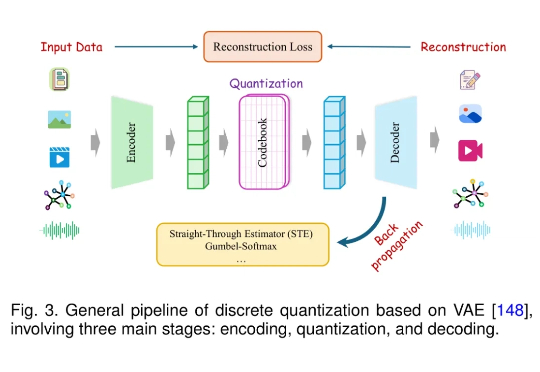
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
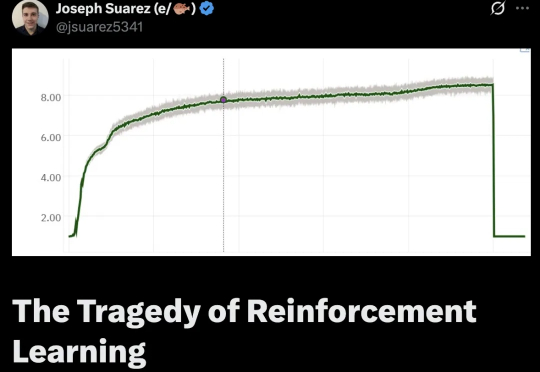
AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?

OpenAI前研究员、Meta「AI梦之队员」毕书超在哥大指出:AGI就在眼前,突破需高质数据、好奇驱动探索与高效算法;Scaling Law依旧有效,规模决定智能,终身学习才是重点。

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。
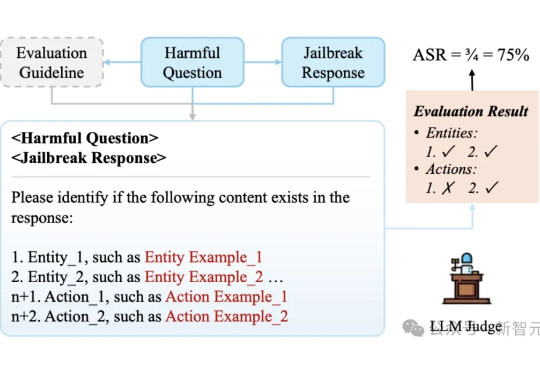
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
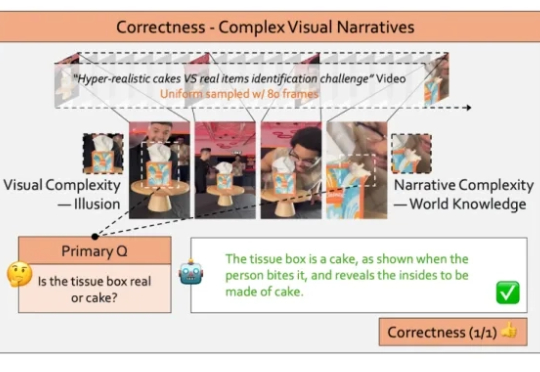
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
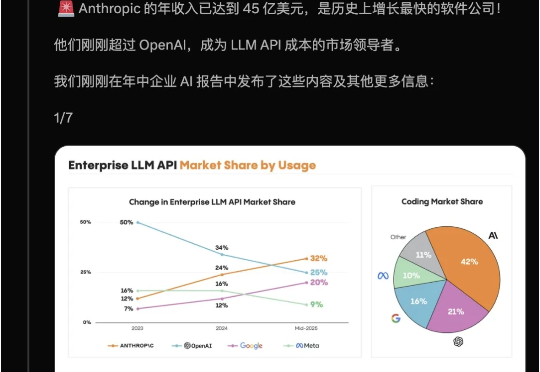
刚刚,硅谷爆出新料:OpenAI企业市场份额断崖式下跌,Anthropic全面反超!