所有实验室都怕字节,所有人都在夸DeepSeek!美国研究员36小时中国AI行
所有实验室都怕字节,所有人都在夸DeepSeek!美国研究员36小时中国AI行中国AI研究员的性格、魅力和真诚……让人倍感亲切。这是艾伦研究所(Ai2)的研究员Nathan Lambert,在最近结束中国之行后,发自内心的一番感慨。在Nathan眼里,国内的LLM圈子简直是天堂,大家彼此尊重、即便立场不同也客客气气的。
来自主题: AI资讯
9592 点击 2026-05-08 14:07
 搜索
搜索
中国AI研究员的性格、魅力和真诚……让人倍感亲切。这是艾伦研究所(Ai2)的研究员Nathan Lambert,在最近结束中国之行后,发自内心的一番感慨。在Nathan眼里,国内的LLM圈子简直是天堂,大家彼此尊重、即便立场不同也客客气气的。
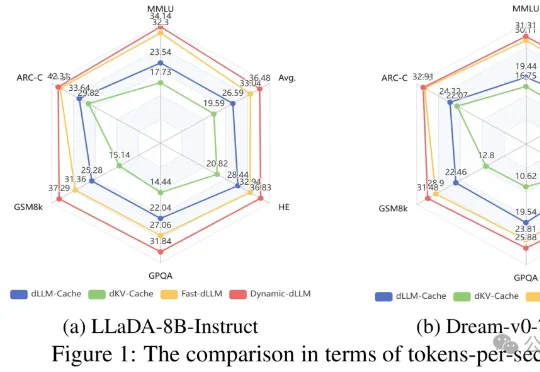
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),
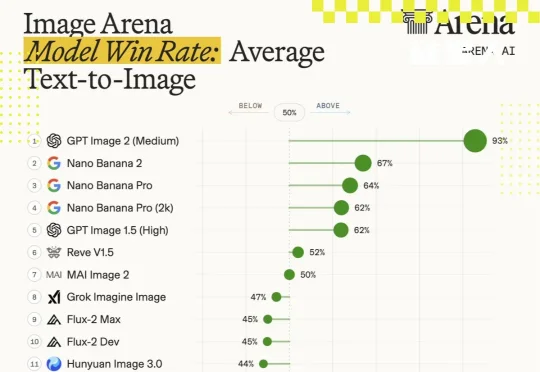
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

美西时间4月28日,具身智能行业有史以来,第一场全球性峰会在硅谷落幕!这场大会星光熠熠—— 2015年图灵奖得主、公钥密码学奠基人Martin Hellman做开场主旨演讲,主题是「安全、智能与物理世界的交汇」。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
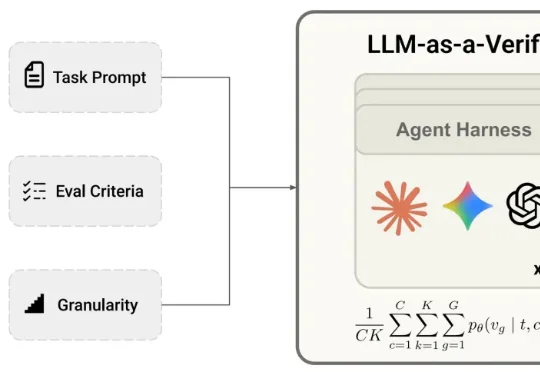
Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。
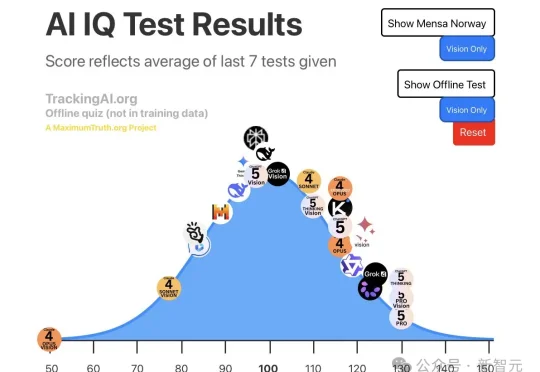
1946年至今,「人类最高智商俱乐部」门萨将迎来第一位非人类成员。根据LisanBench最新跑分,GPT-5.5 Pro文本IQ 130踩上门萨会员线,视觉IQ直接飙到145,杀进天才区。一年前「LLM过不了130」还是技术圈共识,今天,这堵墙彻底被砸碎!
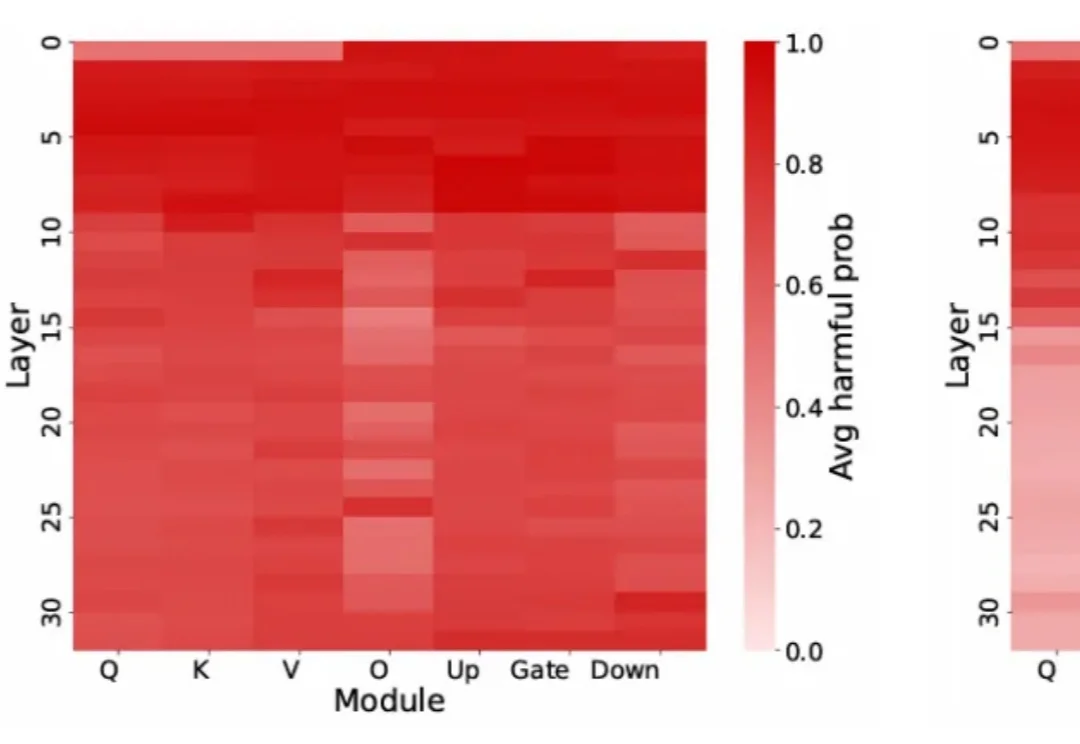
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!