dLLM的「Free Lunch」!浙大&蚂蚁利用中间结果显著提升扩散语言模型
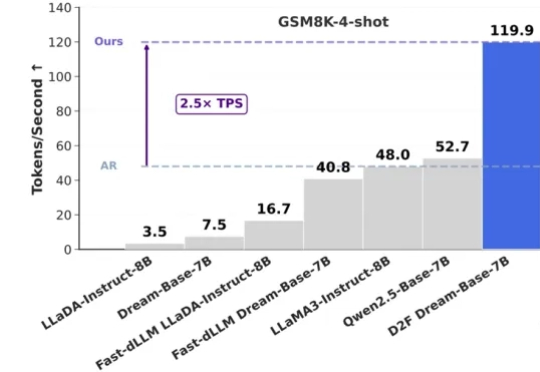
dLLM的「Free Lunch」!浙大&蚂蚁利用中间结果显著提升扩散语言模型近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
来自主题: AI技术研报
9063 点击 2025-08-20 16:26