
用神经架构搜索给LLM瘦身,模型变小,准确度有时反而更高
用神经架构搜索给LLM瘦身,模型变小,准确度有时反而更高大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。
来自主题: AI技术研报
10908 点击 2024-06-11 10:06
 搜索
搜索
大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
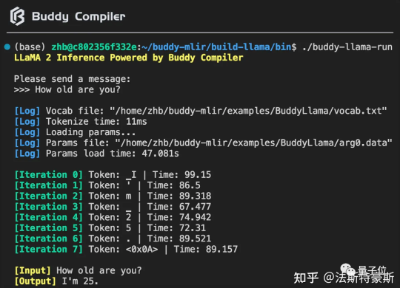
Buddy Compiler 端到端 LLaMA2-7B 推理示例已经合并到 buddy-mlir仓库[1]主线。我们在 Buddy Compiler 的前端部分实现了面向 TorchDynamo 的第三方编译器,从而结合了 MLIR 和 PyTorch 的编译生态。
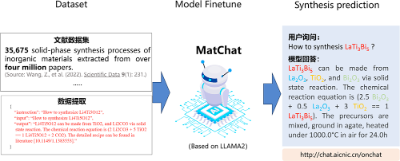
中国科学院物理研究所/北京凝聚态物理国家研究中心SF10组和中国科学院计算机网络信息中心共同合作,将AI大模型应用于材料科学领域,将数万个化学合成路径数据投喂给大语言模型LLAMA2-7b,从而获得了MatChat模型