
Llama 4发布在即,Meta AI负责人突然官宣离职
Llama 4发布在即,Meta AI负责人突然官宣离职Meta AI研究副总裁Pineau亲自发帖声称将于5月30日离职,她主导了Llama开源系列及PyTorch项目。此举正逢扎克伯格重金投入AI及LlamaCon AI大会前夕,引发业内对Meta战略调整和未来新作的诸多猜测。
来自主题: AI资讯
11068 点击 2025-04-05 01:09
 搜索
搜索
Meta AI研究副总裁Pineau亲自发帖声称将于5月30日离职,她主导了Llama开源系列及PyTorch项目。此举正逢扎克伯格重金投入AI及LlamaCon AI大会前夕,引发业内对Meta战略调整和未来新作的诸多猜测。
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
家人们震惊了!现在 AI 成精啦,不仅能写能画,现在连唱功都是格莱美级的了!

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。

在 2024 年七月的一篇博客文章中,Meta CEO 马克·扎克伯格表示,“出售访问权限”给 Meta 公开可用的 Llama AI 模型“不是 Meta 的商业模式。”

Meta此举,或是要证明他们大规模投资AI基础设施不是在蛮干。

马克·扎克伯格今年正在提升 Meta 人工智能的语音功能,准备从这项快速发展技术中创收。

虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。
国家网络安全通报中心昨天扔了个"炸弹":大模型工具Ollama有安全漏洞! 相信不少人用ollama来跑DeepSeek、Llama等模型,确实很方便。可通报里说,它默认开放的11434端口跟没锁的大门似的,谁都能进。今天就和你就说一下 这到底是怎么回事?顺便手把手教你几招,保住你的算力和隐私。
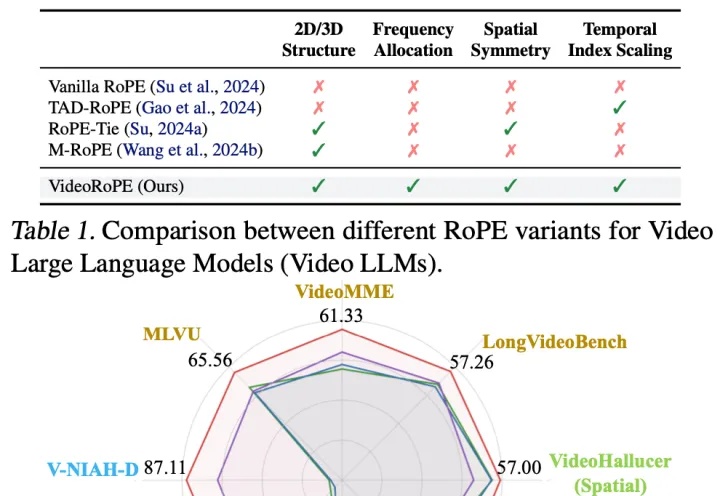
Llama都在用的RoPE(旋转位置嵌入)被扩展到视频领域,长视频理解和检索更强了。