# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。研究者不仅开源了Prompt模板还开源了代码,如果您对o1曾经感兴趣,也应该关注一下这个框架。
从OpenAI的GPT系列到Anthropic的Claude,这些模型展现出了令人瞩目的知识储备和推理能力,能够处理从简单问答到复杂推理的各类任务。特别是通过Chain-of-Thought(CoT)、Tree of Thoughts(ToT)等技术的发展,这些模型已经能够将复杂问题分解为多个简单步骤来逐步解决。

然而,当前的大语言模型推理框架存在一个根本性问题:推理过程是不透明的黑盒,缺乏对知识检索和推理步骤的明确区分。这种模糊性导致了两个严重的挑战:
1.幻觉(Hallucination)问题
2.遗忘(Forgetting)问题
这些挑战在处理多跳推理(Multi-hop Reasoning)等复杂任务时表现得尤为突出。例如,当模型需要通过多个推理步骤得出结论时,它往往难以有效地在每个步骤中利用已知信息,导致推理链断裂或得出错误结论。
为了应对这些挑战,现有的研究主要集中在两个方向:
1.基于记忆的方法
2.基于推理的方法
然而,这些方法往往是割裂的,未能有效解决知识运用和推理能力的协同问题。为此,来自罗格斯大学、俄亥俄州立大学和加州大学圣塔芭芭拉分校的研究团队提出了一种突破性的解决方案:通过显式地分离记忆和推理过程,构建一个新的推理范式。这种方法不仅提高了模型的性能,更为重要的是增强了推理过程的可解释性,使我们能够更好地理解和改进模型的决策过程。

原文地址:https://arxiv.org/abs/2411.13504
代码:https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning/tree/main
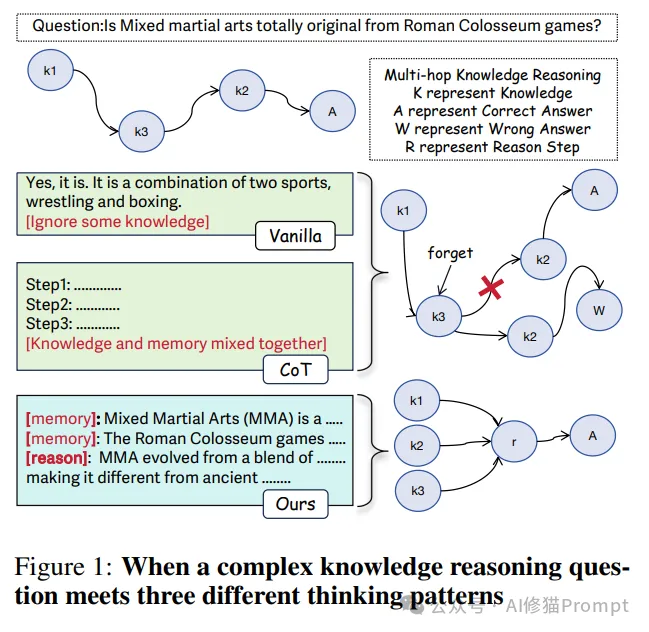
在大语言模型的发展历程中,如何有效地处理复杂推理任务一直是一个重要而富有挑战性的问题。本研究提出了一种创新的解决方案,通过将记忆和推理过程解耦,不仅显著提升了模型的推理能力,更为重要的是增强了推理过程的可解释性。
研究者的方法建立在一个关键观察之上:在人类的认知过程中,记忆检索和逻辑推理是两个相互关联但又相对独立的认知功能。基于这一认识,研究者设计了一种新的推理范式,通过显式地分离这两个过程,使大语言模型能够更有效地处理复杂的推理任务。
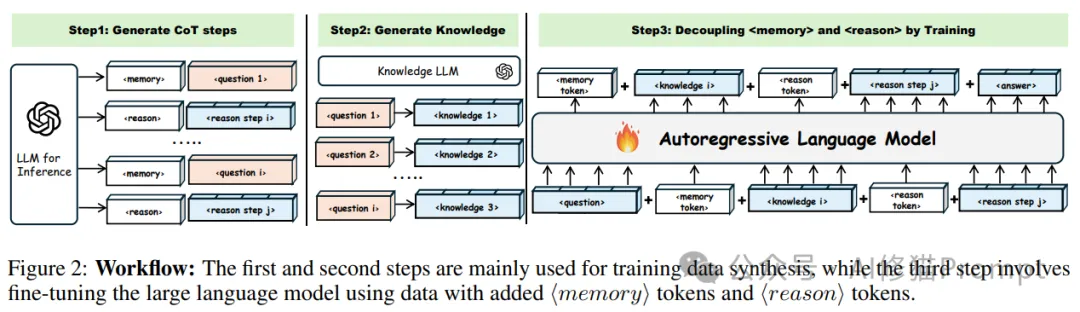
研究者的解决方案包含两个核心创新:双LLM协同框架和特殊标记引导机制。在双LLM框架中,知识LLM负责准确的知识检索,而推理LLM则专注于逻辑推理过程。这种分工不仅提高了各自的专业性,也使整个推理过程更加清晰和可控。
特殊标记⟨memory⟩和⟨reason⟩的引入则是另一个关键创新。这些标记不是简单的分类标签,而是作为可训练的特殊词汇,在训练过程中学习如何更好地引导模型在不同认知模式之间切换。通过这种方式,模型能够更好地理解和执行复杂的推理任务。
在研究者提出的框架中,推理LLM和知识LLM形成了一个紧密协作的系统。推理LLM首先接收用户的问题,通过生成详细的思维链步骤,明确标识出需要知识支持的环节和纯粹的推理步骤。这些步骤不是简单的线性序列,而是经过精心设计的推理路径,确保每个推理步骤都有充分的知识支持。
知识LLM则专注于提供准确、相关的知识支持。它不仅回答推理LLM提出的问题,还要确保提供的知识是准确的、相关的,并且能够有效支持后续的推理过程。这种协作机制确保了推理过程既有坚实的知识基础,又保持了清晰的逻辑结构。
为了确保生成数据的质量,研究者建立了一套完整的质量保证机制。在知识验证方面,研究者采用多源交叉验证的方式,确保知识的准确性。通过比对不同来源的信息,研究者可以识别和过滤掉可能的错误或不准确的知识。
在推理有效性方面,研究者重点关注推理步骤的逻辑连贯性和完整性。每个推理步骤都需要经过严格的逻辑验证,确保推理链的完整性和结论的可靠性。这种严格的质量控制确保了训练数据的高质量,为模型的有效学习奠定了基础。
研究者设计了一种特殊的训练数据结构,将每个训练实例分解为三个主要部分:问题、思维过程和答案。这种结构不是简单的线性序列,而是经过精心设计的层次化结构,确保模型能够学习到知识获取和推理的有效模式。
在问题部分,研究者保留了问题的完整语义信息。思维过程部分则是记忆和推理步骤的交织序列,每个步骤都有明确的标识和目的。这种结构设计使模型能够更好地理解和学习复杂的推理模式。
在训练策略上,研究者采用了多层次的优化方案。首先,通过标准的自回归训练方式,确保模型能够有效学习序列生成的基本能力。其次,使用LoRA微调技术,在保持模型核心能力的同时,有效地适应新的任务需求。
特殊标记的训练是另一个关键环节。这些标记不是简单的分类标签,而是作为可训练的特殊词汇,在训练过程中学习如何更好地引导模型在不同认知模式之间切换。通过精心设计的损失函数和训练策略,确保这些标记能够有效发挥其引导作用。
为了全面验证研究者提出方法的有效性,研究团队设计并执行了一系列严谨的实验。这些实验不仅验证了方法的可行性,更重要的是展示了其在多个具有挑战性的任务上的卓越表现。
在模型选择上,研究者采用了一种多层次的验证策略。作为主要的验证对象,研究者选择了三个具有代表性的大语言模型:LLaMA-2-7B-chat-hf、LLaMA-3.1-8B-Instruct和Qwen2.5-7B-Instruct。这些模型不仅代表了不同的技术路线,也反映了不同的模型规模和能力水平。
为了确保实验的可靠性,研究者还引入了GPT-4o作为辅助模型,用于生成高质量的训练数据和进行结果评估。这种设计确保了研究者能够获得可靠的训练数据,同时也为实验结果提供了可靠的评估基准。
在数据集的选择上,研究者特别关注了不同类型的推理能力。StrategyQA数据集要求模型进行多步推理,这对模型的推理能力提出了较高的要求。CommonsenseQA则侧重于常识性推理,这种推理往往需要模型具备广泛的知识基础和灵活的推理能力。
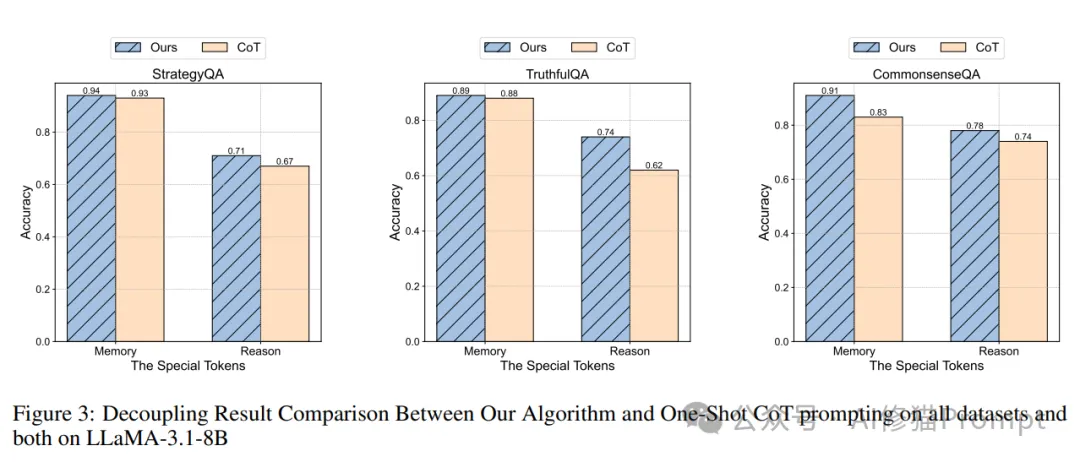
TruthfulQA数据集的引入则体现了研究者对模型真实性的重视。这个数据集不仅测试模型的推理能力,更重要的是考察模型在面对具有误导性的问题时能否保持准确性。为了确保评估的公平性,研究者对数据集进行了适当的预处理,包括将问题转化为统一的单选题格式,并通过打乱选项顺序来防止模型学习到不相关的模式。
为了全面评估研究者方法的优势,研究团队设置了多个具有代表性的基线方法。零样本推理代表了模型的基础能力,思维链(CoT)则反映了当前主流的推理增强方法。通过引入LoRA微调和Planning-token等方法作为基线,研究者能够更好地理解该方法在不同方面的优势。

实验结果展示了研究者方法的显著优势。在StrategyQA数据集上,使用该方法微调的Qwen 2.5-7B模型达到了78.0%的准确率,这不仅显著超过了传统的CoT方法(69.6%),也优于当前最先进的Planning-token方法(77.4%)。这个结果特别值得关注,因为StrategyQA是一个需要复杂推理能力的数据集。
在CommonsenseQA数据集上,研究者的方法同样展现出色的表现。LLaMA-3.1-8B模型达到了82.3%的准确率,这个成绩不仅大幅领先于基线方法,也展示了该方法在处理常识推理任务时的优势。特别值得注意的是,即使在较小规模的LLaMA-2-7B模型上,该方法也取得了显著的性能提升。
最令人瞩目的是在TruthfulQA数据集上的表现。研究者的方法使LLaMA-3.1-8B模型达到了86.6%的准确率,这个成绩不仅超越了各种基线方法,更重要的是首次在这个数据集上超越了GPT-4o 85.4%的性能。这个结果充分证明了该方法在提高模型可靠性和真实性方面的优势。
为了深入理解不同组件的贡献,研究者进行了详细的消融研究。在记忆和推理标记的贡献分析中,研究者发现这些特殊标记的存在确实显著提升了模型的性能。当研究者随机化这些标记时,模型的性能出现明显下降,这证实了解耦设计的必要性。
在特殊标记数量的研究中,研究者发现4-6个标记能够达到最佳效果。这个发现不仅具有实践意义,也为理解模型的工作机制提供了重要线索。通过对比零标记训练的结果,研究者还排除了性能提升可能来自知识蒸馏的可能性,进一步证实了该方法的有效性。
在案例分析中,研究者深入研究了模型的工作机制。通过注意力分析,研究者观察到特殊标记确实获得了较高的注意力权重,这证实了它们在引导模型行为方面的重要作用。可视化分析不仅提供了直观的证据,也帮助研究者更好地理解模型的决策过程。
错误分析则揭示了一个有趣的现象:在不同数据集上,推理错误始终占据主导地位(约75-98%),而记忆错误的比例相对较低。这个发现不仅证实了该方法在知识获取方面的有效性,也为未来的研究指明了方向:如何进一步提升模型的推理能力仍然是一个值得关注的问题。

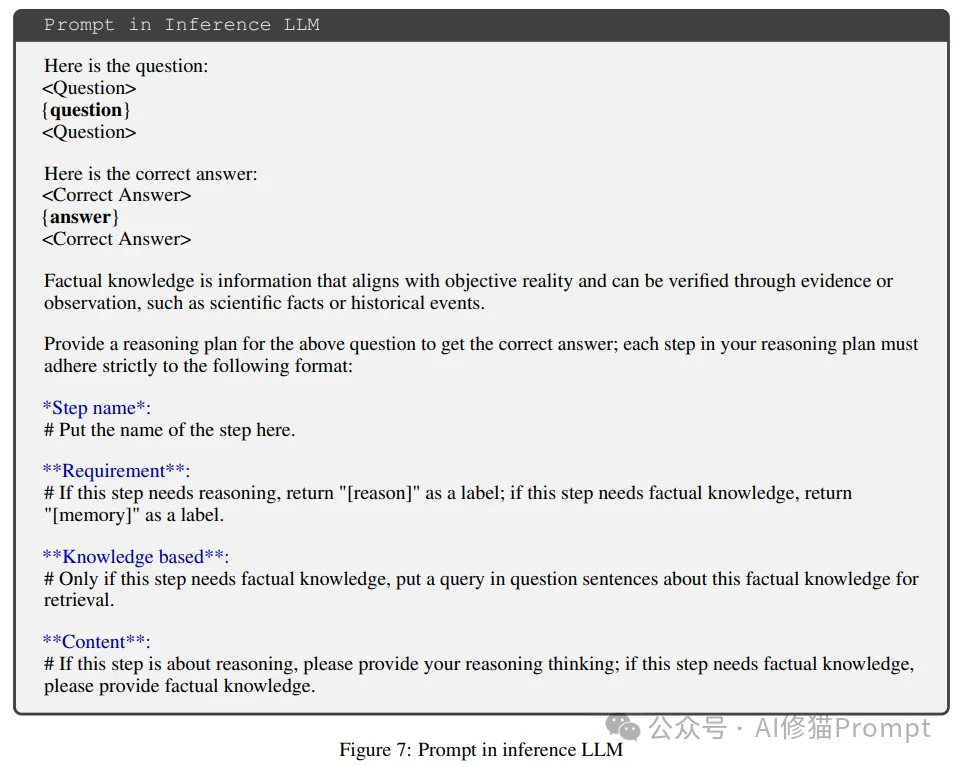


通过显式解耦记忆与推理过程,结合先进的技术框架和创新的训练方法,研究者提出的这种新范式为大语言模型的推理能力带来了革命性的提升。在提示词优化和模型微调方向有需求的朋友可以仔细研究一下这个方法,会为你带来不一样的收获。欢迎和我交流,以下是之前文章的资料赠予介绍。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
