
多模态模型免微调接入互联网,即插即用新框架,效果超闭源商用方案
多模态模型免微调接入互联网,即插即用新框架,效果超闭源商用方案一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。
来自主题: AI技术研报
5198 点击 2024-11-10 14:40
 搜索
搜索
一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。

视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
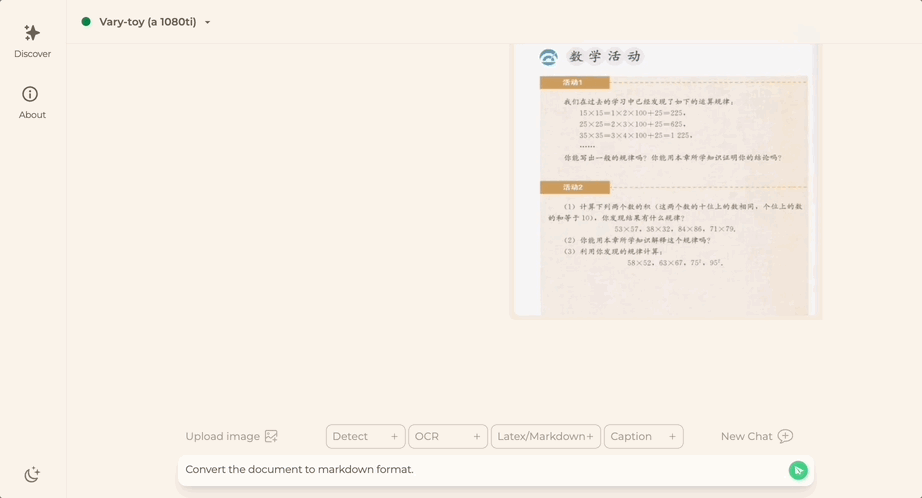
一款名为Vary-toy的“年轻人的第一个多模态大模型”来了!模型大小不到2B,消费级显卡可训练,GTX1080ti 8G的老显卡轻松运行。

基于LVLM幻觉频发的三个成因(物体共现、物体不确定性、物体位置),北卡教堂山、斯坦福、哥大、罗格斯等大学的研究人员提出幻觉修正器LURE,通过修改描述来降低幻觉问题。