均值至上假繁荣!北大新作专挑难题,逼出AI模型真本事
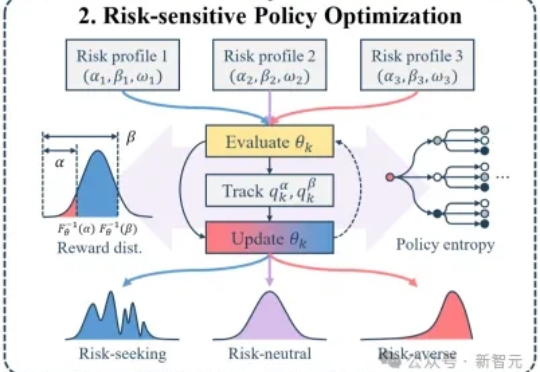
均值至上假繁荣!北大新作专挑难题,逼出AI模型真本事大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
来自主题: AI技术研报
7930 点击 2025-10-25 14:32
 搜索
搜索
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
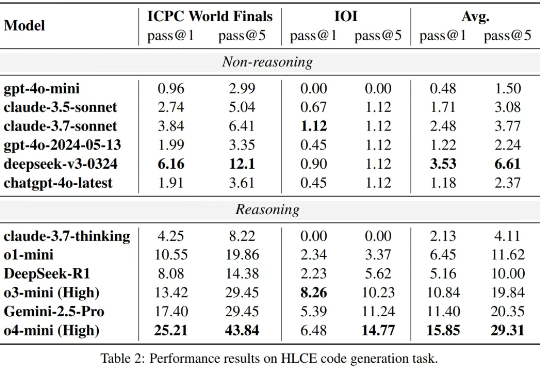
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
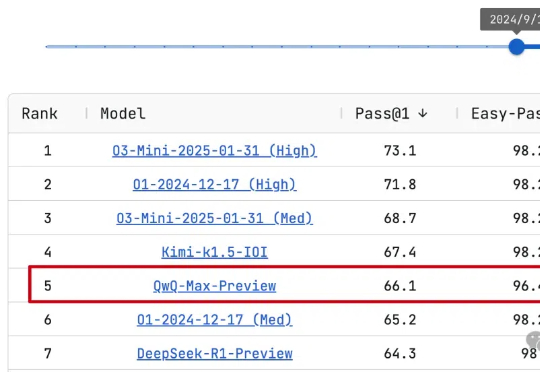
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
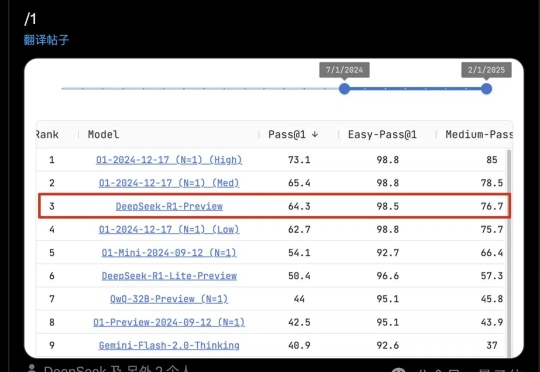
DeepSeek版o1,有消息了。还未正式发布,已在代码基准测试LiveCodeBench霸榜前三,表现与OpenAI o1的中档推理设置相当。注意了,这不是在DeepSeek官方App已经能试玩的DeepSeek-R1-Lite-Preview(轻量预览版)。