58行代码把Llama 3扩展到100万上下文,任何微调版都适用
58行代码把Llama 3扩展到100万上下文,任何微调版都适用堂堂开源之王Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。
来自主题: AI资讯
10907 点击 2024-05-06 20:51
 搜索
搜索
堂堂开源之王Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。

随着 Llama 3 发布,未来大模型的参数量已飙升至惊人的 4000 亿。尽管每周几乎都有一个声称性能超强的大模型出来炸场,但 AI 应用还在等待属于它们的「ChatGPT 时刻」。其中,AI 智能体无疑是最被看好的赛道。

AI做数学题,真正的思考居然是暗中“心算”的?
2024 年 4 月 20 日,即 Meta 开源 Llama 3 的隔天,初创公司 Groq 宣布其 LPU 推理引擎已部署 Llama 3 的 8B 和 70B 版本,每秒可输出token输提升至800。

Llama 3的开源,再次掀起了一场大模型的热战,各家争相测评、对比模型的能力,也有团队在进行微调,开发衍生模型。
FP8和更低的浮点数量化精度,不再是H100的“专利”了!
Llama 3诞生整整一周后,直接将开源AI大模型推向新的高度。
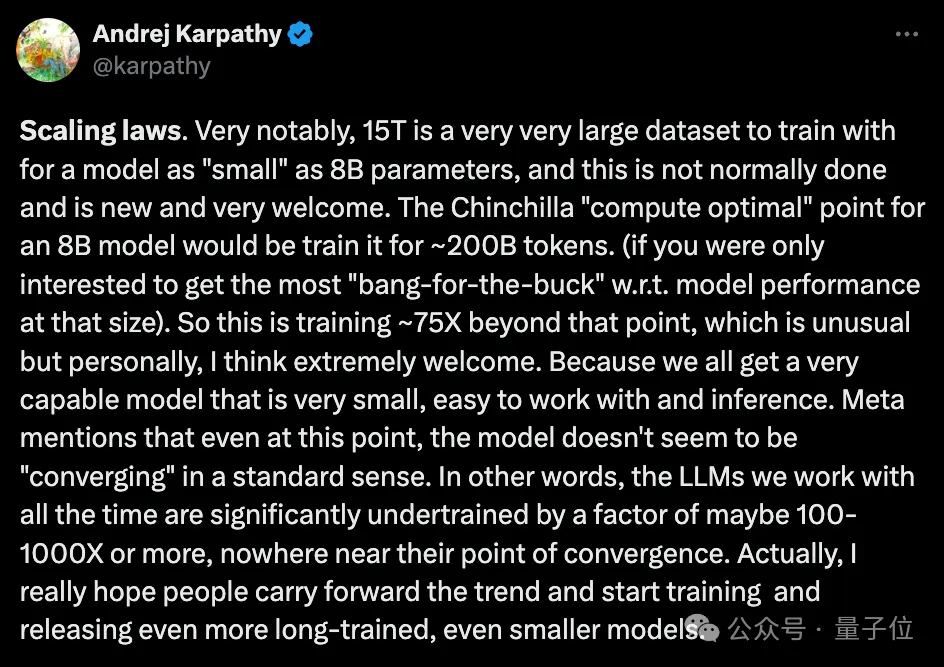
大模型力大砖飞,让LLaMA3演绎出了新高度: 超15T Token数据上的超大规模预训练,既实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。