
革命新架构掀翻Transformer!无限上下文处理,2万亿token碾压Llama 2
革命新架构掀翻Transformer!无限上下文处理,2万亿token碾压Llama 2继Mamba之后,又一敢于挑战Transformer的架构诞生了!
来自主题: AI技术研报
6163 点击 2024-04-17 19:23
 搜索
搜索
继Mamba之后,又一敢于挑战Transformer的架构诞生了!

早前Meta的LLaMA大模型“意外”泄露后,大模型的开源与闭源之争就此提上了日程。大模型到底是开源好、还是闭源好?过去一年整个AI业界可谓是争吵不休。如今,又有一位重量级人士站出来表态了。
一条磁力链,Mistral AI又来闷声不响搞事情。
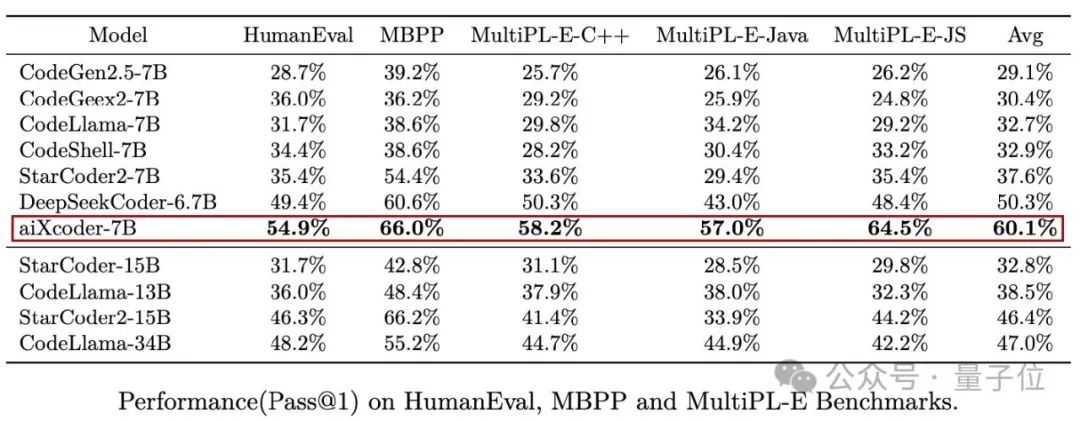
来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。

Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能,据称在某些基准下能超越Llama 2 70B。

近日,天才程序员Justine Tunney发推表示自己更新了Llamafile的代码,通过手搓84个新的矩阵乘法内核,将Llama的推理速度提高了500%!

在大模型落地应用的过程中,端侧 AI 是非常重要的一个方向。近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。

关注 OpenAI核心创始成员Andrej Karpathy 深度分享AI大模型发展及Elon管理法则。近日,OpenAI核心创始成员Andrej Karpathy(已于24年2月离职)在红杉资本进行了一场精彩的分享。
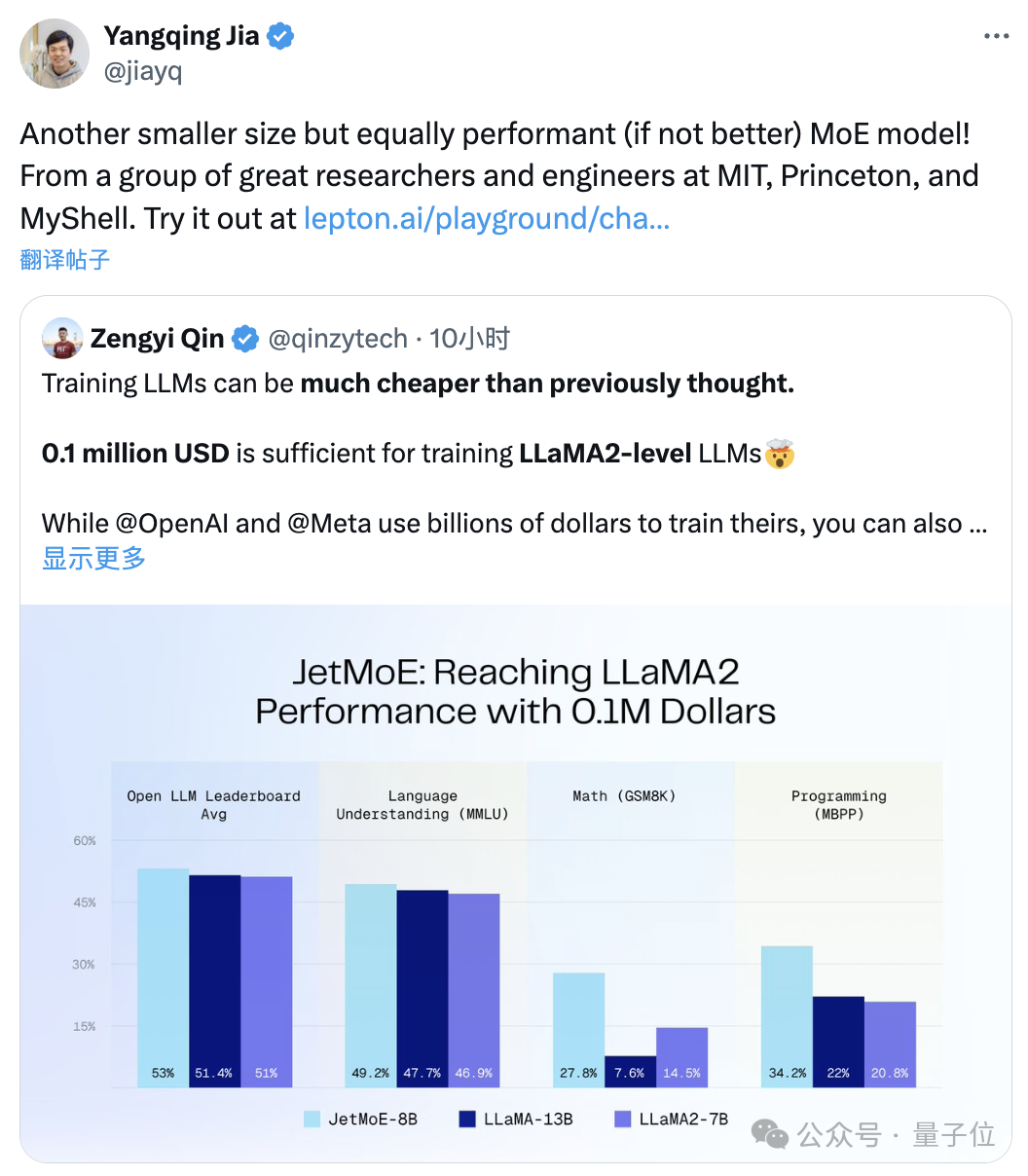
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。