DeepSeek的MLA,任意大模型都能轻松迁移了
DeepSeek的MLA,任意大模型都能轻松迁移了DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
来自主题: AI技术研报
7016 点击 2025-03-07 10:24
 搜索
搜索
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
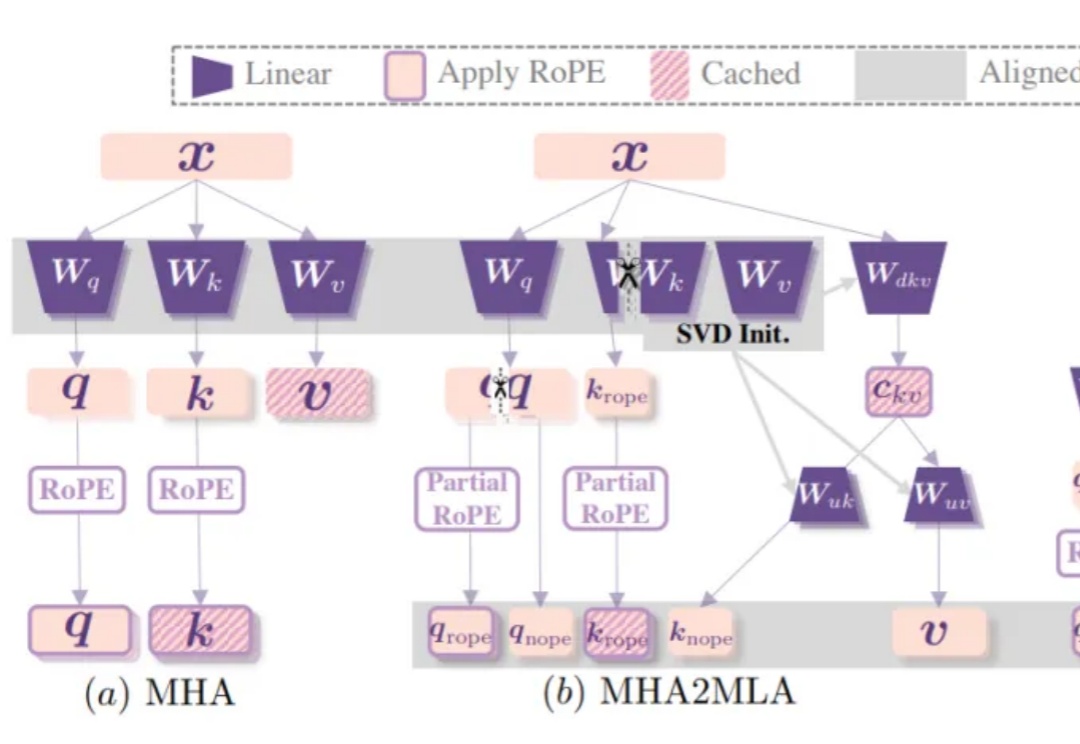
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!