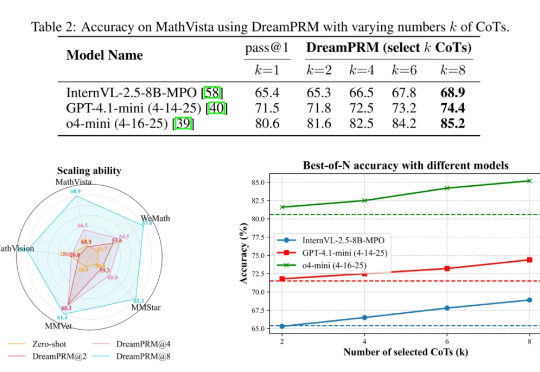
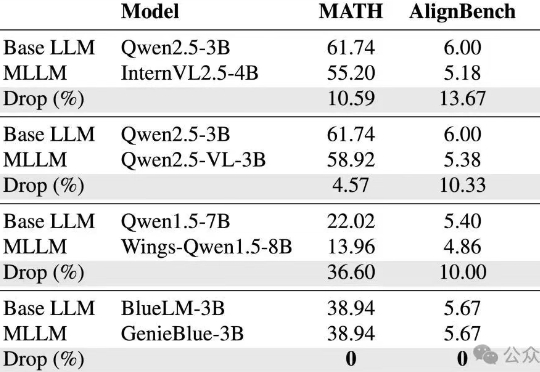
不再靠「猜坐标」!颜水成团队等联合发布PaDT多模态大模型:实现真正的多模态表征输出
不再靠「猜坐标」!颜水成团队等联合发布PaDT多模态大模型:实现真正的多模态表征输出近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
来自主题: AI技术研报
10530 点击 2025-10-16 12:31