多模态大模型对齐新范式,10个评估维度全面提升,快手&中科院&南大打破瓶颈
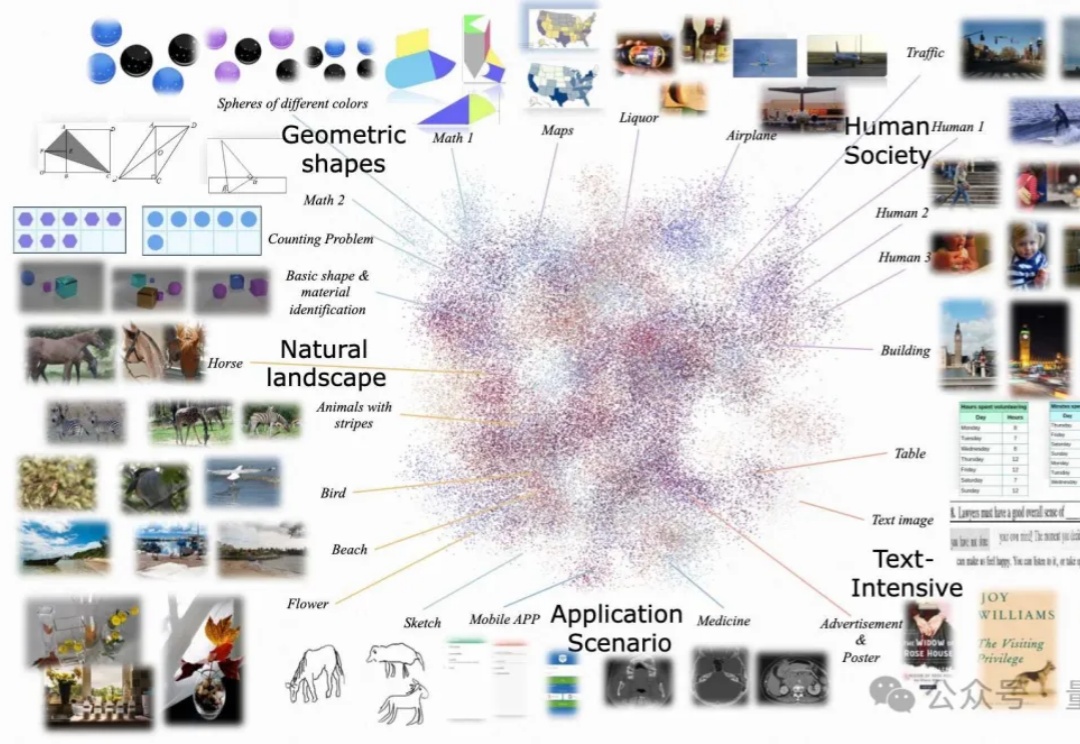
多模态大模型对齐新范式,10个评估维度全面提升,快手&中科院&南大打破瓶颈尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
来自主题: AI技术研报
11530 点击 2025-02-26 14:07
 搜索
搜索
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

近年来,多模态大模型(MLLM)在视觉理解领域突飞猛进,但如何让大语言模型(LLM)低成本掌握视觉生成能力仍是业界难题!
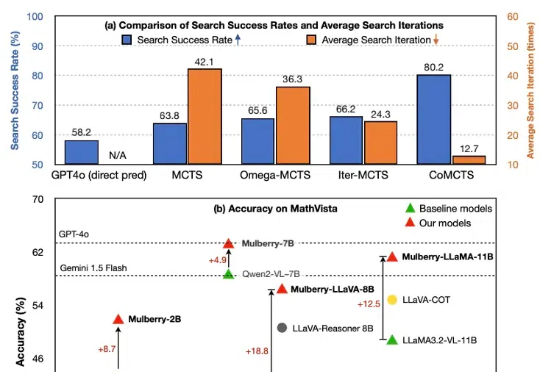
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。
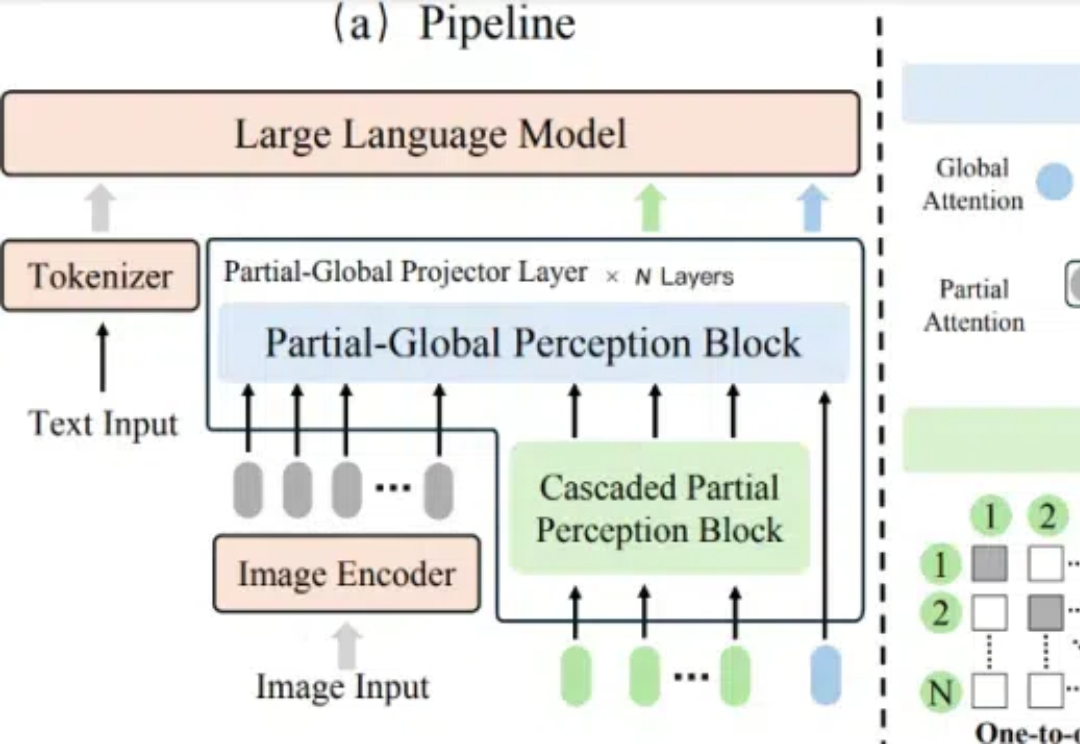
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。
我们生活在一个感官丰富的 3D 世界中,视觉信号围绕着我们,让我们能够感知、理解和与之互动。
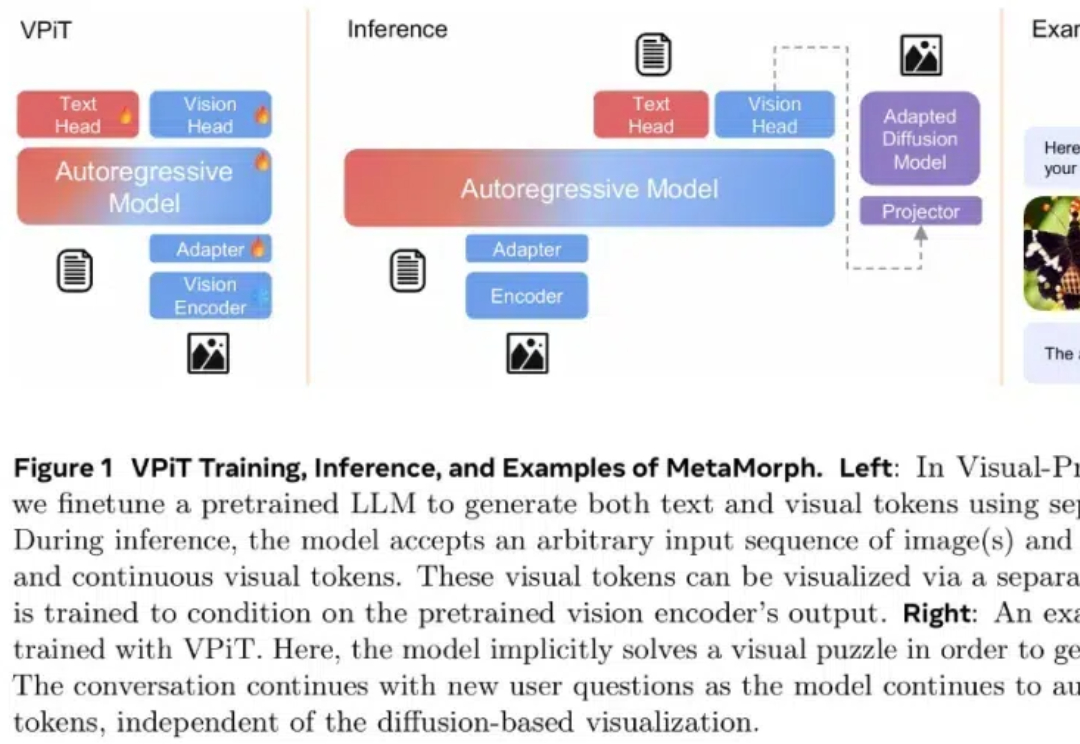
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
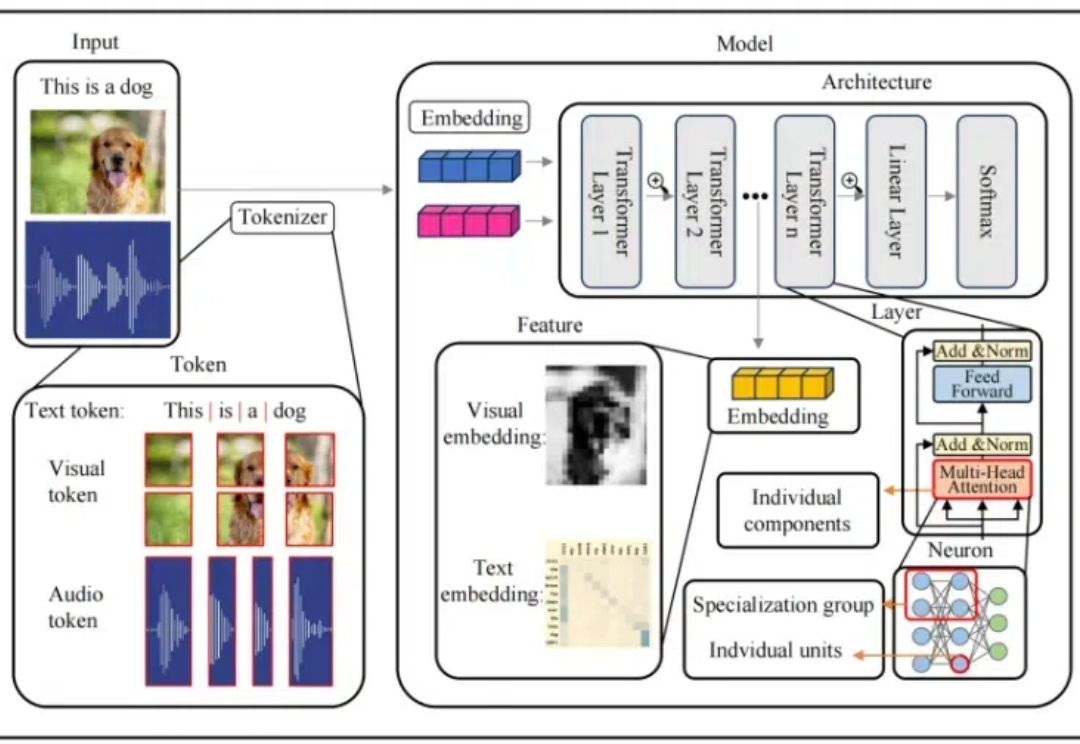
本文介绍了首个多模态大模型(MLLM)可解释性综述
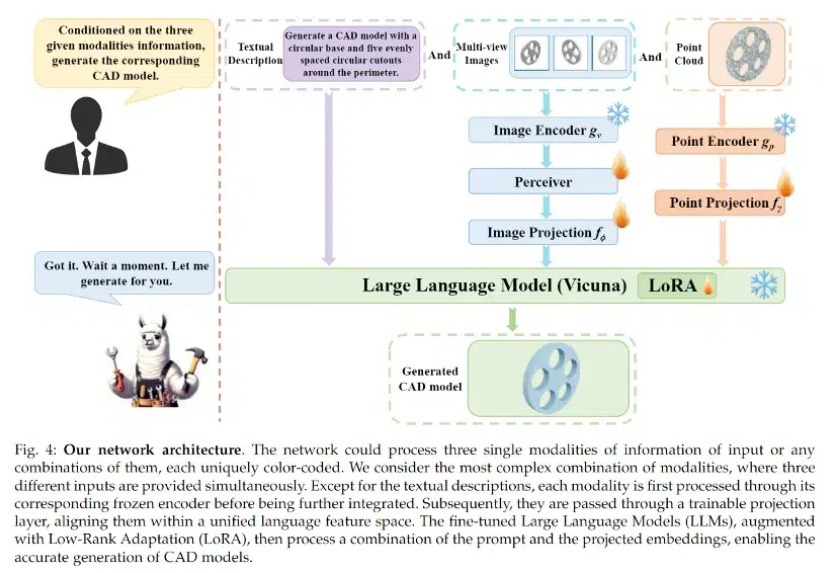
该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
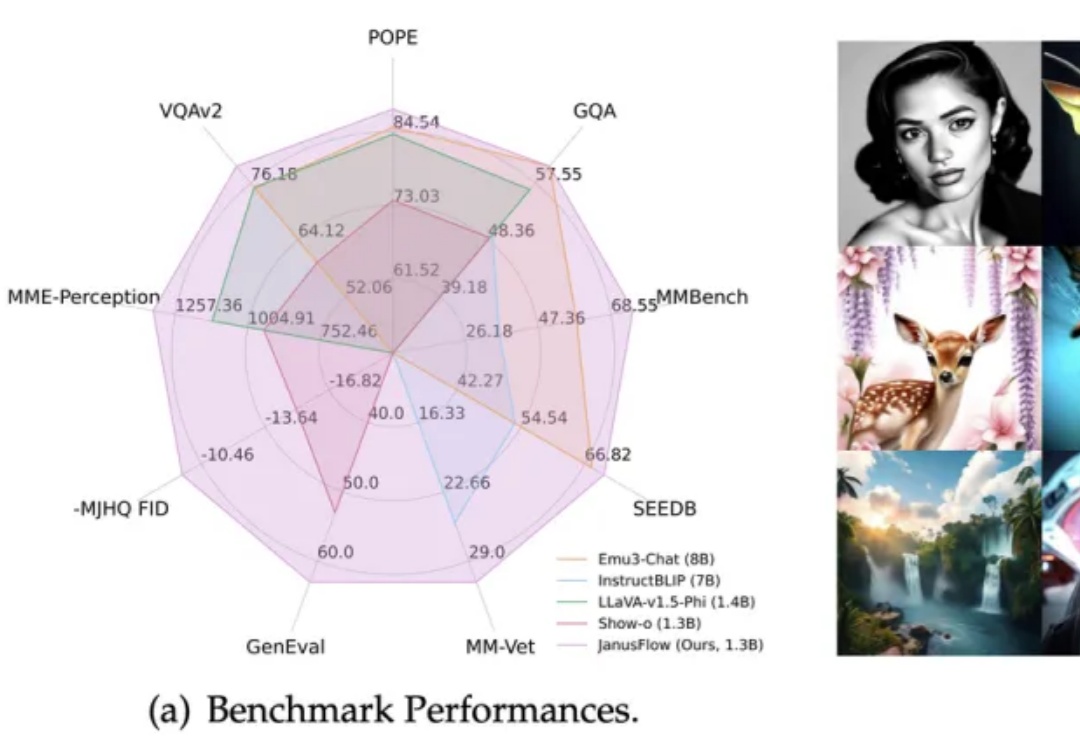
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。