
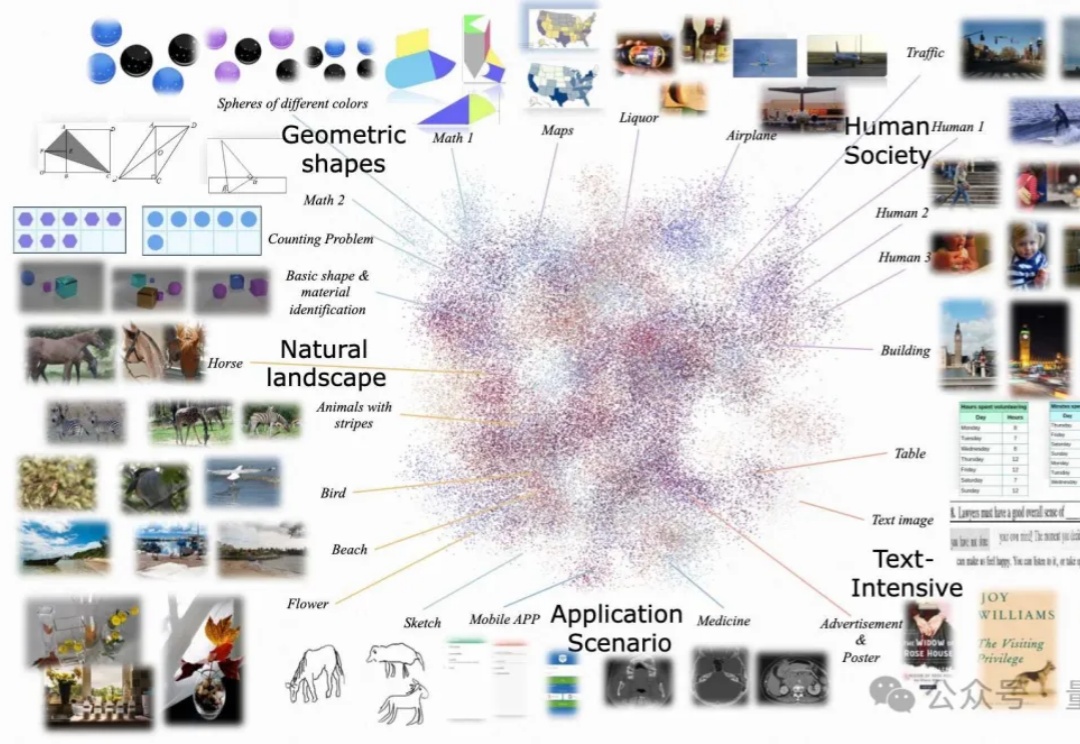
让GPT-4o准确率大降,这个文档理解新基准揭秘大模型短板
让GPT-4o准确率大降,这个文档理解新基准揭秘大模型短板在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
来自主题: AI技术研报
10017 点击 2025-05-25 11:44
 搜索
搜索
在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
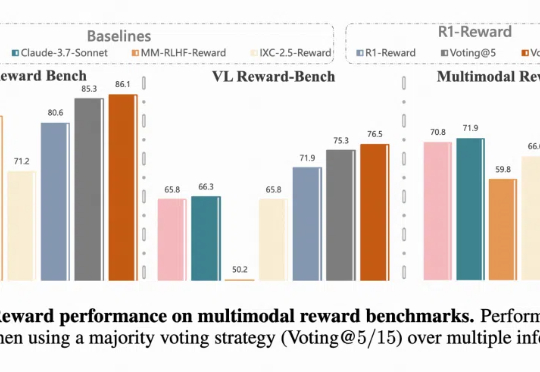
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
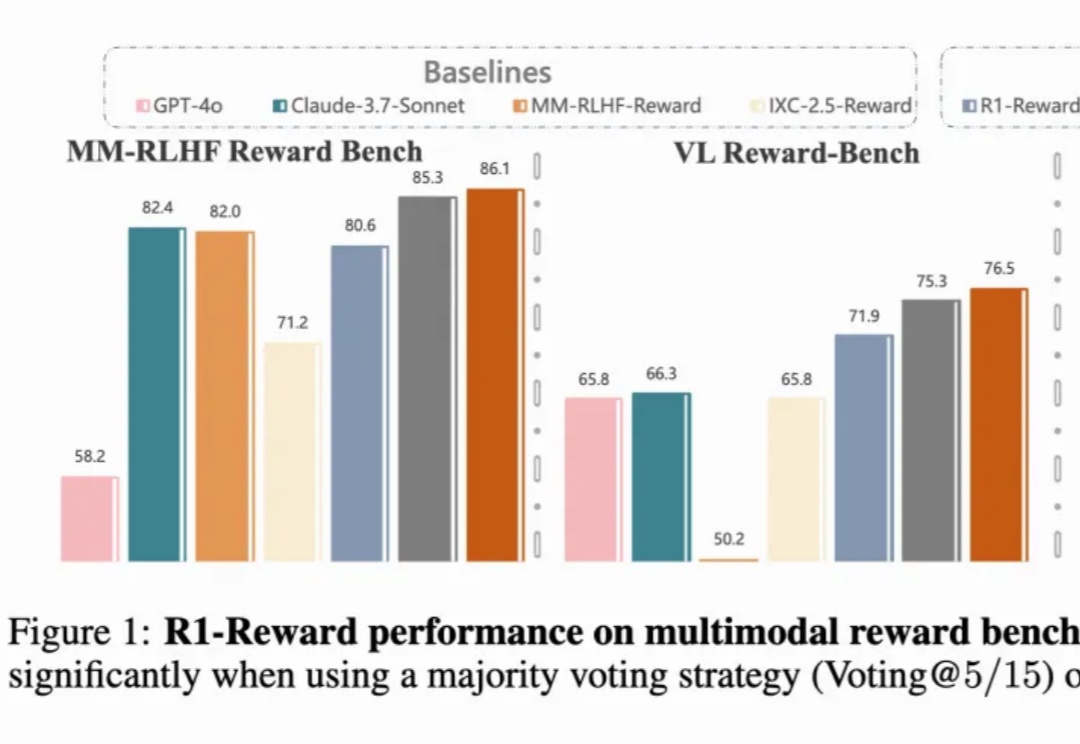
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
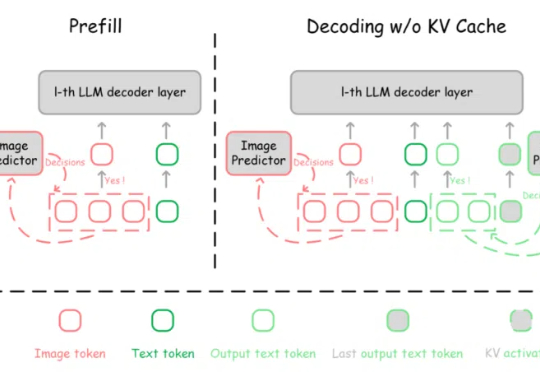
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
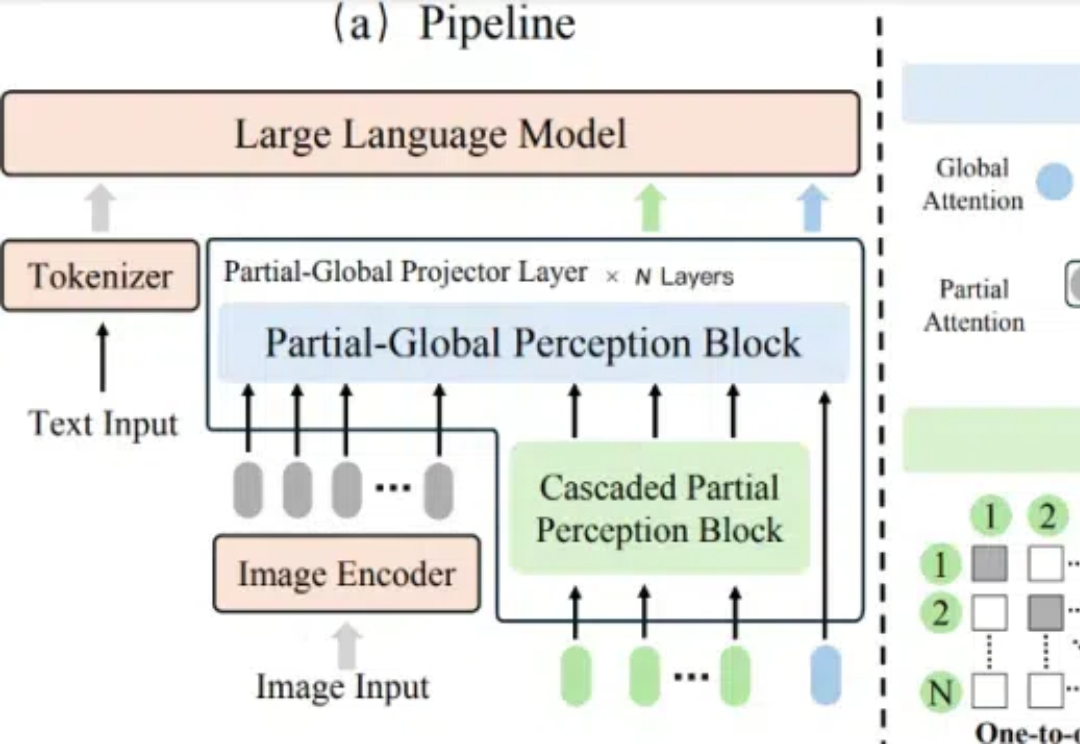
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。

MME-Finance 是一个专为金融领域设计的多模态基准测试,由同花顺财经旗下的 HiThink 研究团队联合多家高校共同开发,旨在评估和提升多模态大型语言模型(MLLMs)在金融领域的专业理解和推理能力。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。