
Claude Code唯一对手!?AI编程黑马AmpCode崛起的秘密:不设token上限,放手让AI自己死磕代码
Claude Code唯一对手!?AI编程黑马AmpCode崛起的秘密:不设token上限,放手让AI自己死磕代码近期,AI 编程领域又一匹 AI Coding 黑马正在快速崛起。
来自主题: AI资讯
10247 点击 2025-07-31 18:16
近期,AI 编程领域又一匹 AI Coding 黑马正在快速崛起。
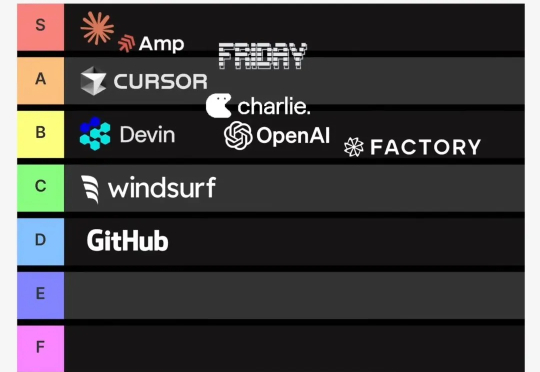
最近这段时间又一匹AI coding黑马正在快速崛起,感兴趣的朋友可以先看下这个视频,在Every最新一期播客里,他们对当前所有AI coding产品做了一个评级分类,而跟Claude code共同排在S级的就是最近Sourcegraph刚推出的Ampcode,而爆火的Cursor也只排在了第二档次的A级。
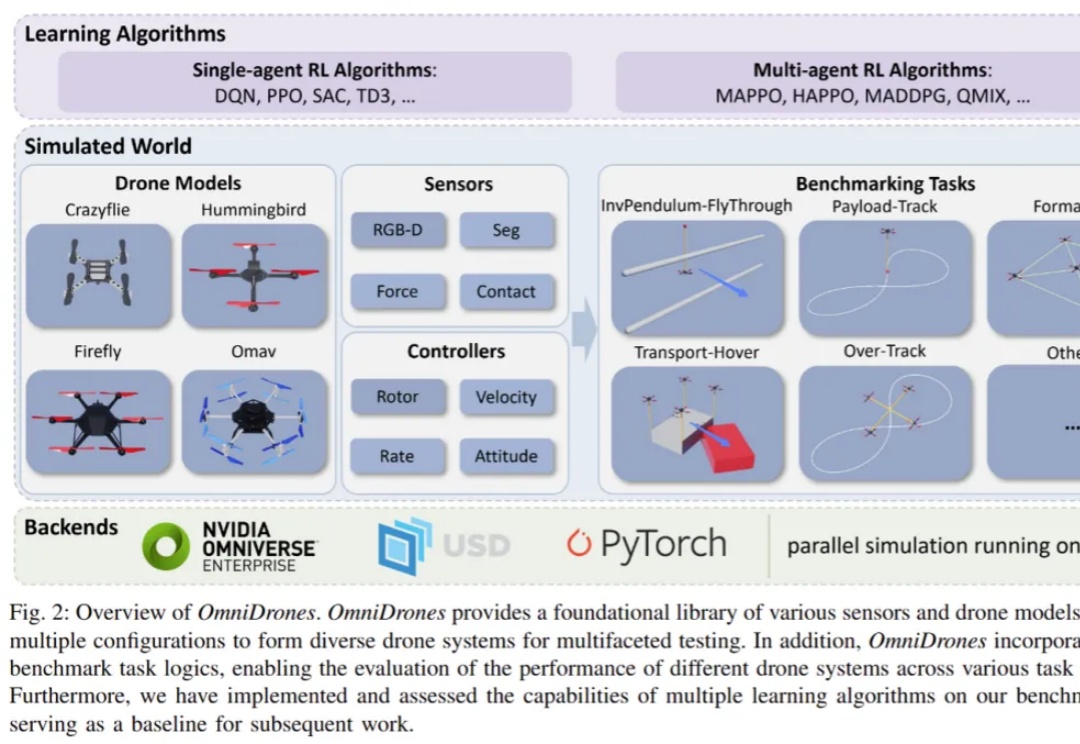
控制无人机执行敏捷、高机动性的行为是一项颇具挑战的任务。传统的控制方法,比如 PID 控制器和模型预测控制(MPC),在灵活性和效果上往往有所局限。而近年来,强化学习(RL)在机器人控制领域展现出了巨大的潜力。通过直接将观测映射为动作,强化学习能够减少对系统动力学模型的依赖。
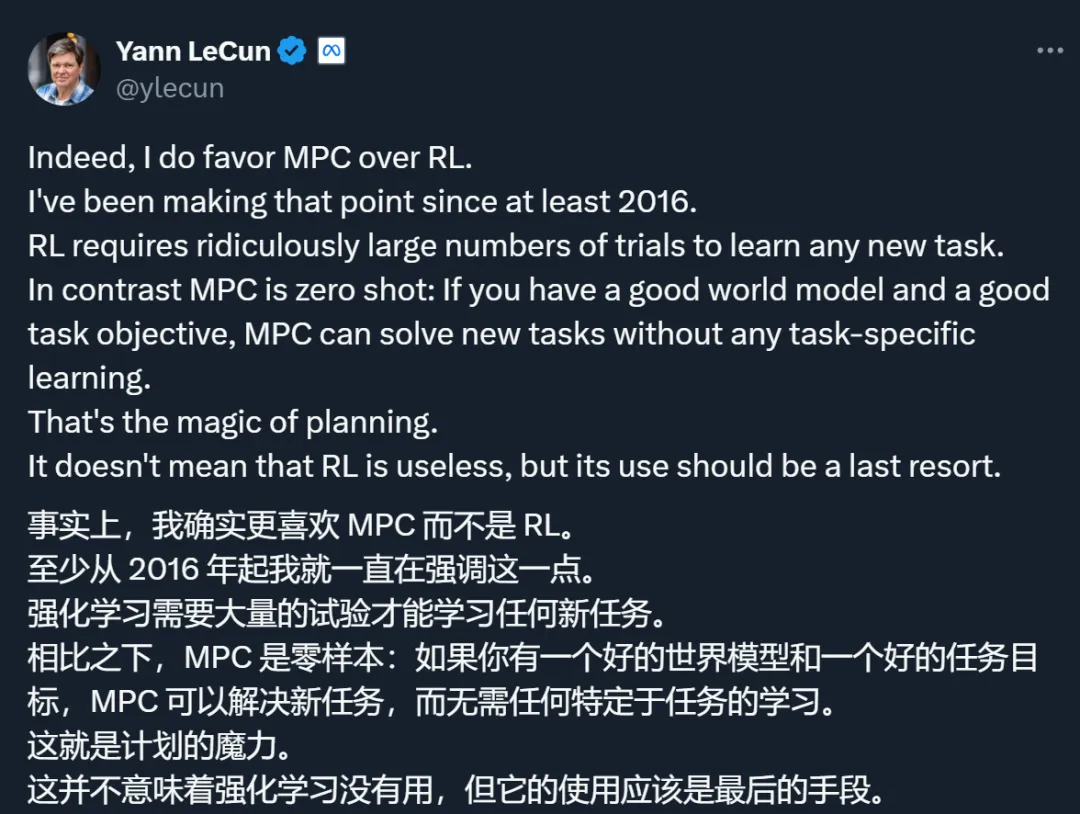
「相比于强化学习(RL),我确实更喜欢模型预测控制(MPC)。至少从 2016 年起,我就一直在强调这一点。强化学习在学习任何新任务时都需要进行极其大量的尝试。相比之下,模型预测控制是零样本的:如果你有一个良好的世界模型和一个良好的任务目标,模型预测控制就可以在不需要任何特定任务学习的情况下解决新任务。这就是规划的魔力。这并不意味着强化学习是无用的,但它的使用应该是最后的手段。」