
36 亿融资“造假”被揭穿,挣钱太难了,前苹果 AI 工程师 3 年打造的“欧洲 OpenAI”宣告退出模型竞赛
36 亿融资“造假”被揭穿,挣钱太难了,前苹果 AI 工程师 3 年打造的“欧洲 OpenAI”宣告退出模型竞赛近日 Aleph Alpha 开始将其商业重点从开发大型语言模型转向生成式 AI 操作系统和咨询服务。
来自主题: AI资讯
10284 点击 2024-09-11 09:33
 搜索
搜索
近日 Aleph Alpha 开始将其商业重点从开发大型语言模型转向生成式 AI 操作系统和咨询服务。

性能不输Mistral与Llama,优化多语言支持,强化合规性。

只要不到10行代码,就能让大模型数学能力(GSM8k)提升20%!

TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。

7 月,大模型公司 Cohere 宣布 D 轮融资 5 亿美元,估值 55 亿,比去年高了一倍多。 跟 OpenAI、Anthropic 甚至法国 AI 公司 Mistral 相比,成立于加拿大的 Cohere 略显低调,没有推出自己的 Chatbot、文生图或者文生视频产品,不涉足个人消费端产品;即使是推出的开源大模型 Command R+,似乎也没有那么引人注意。
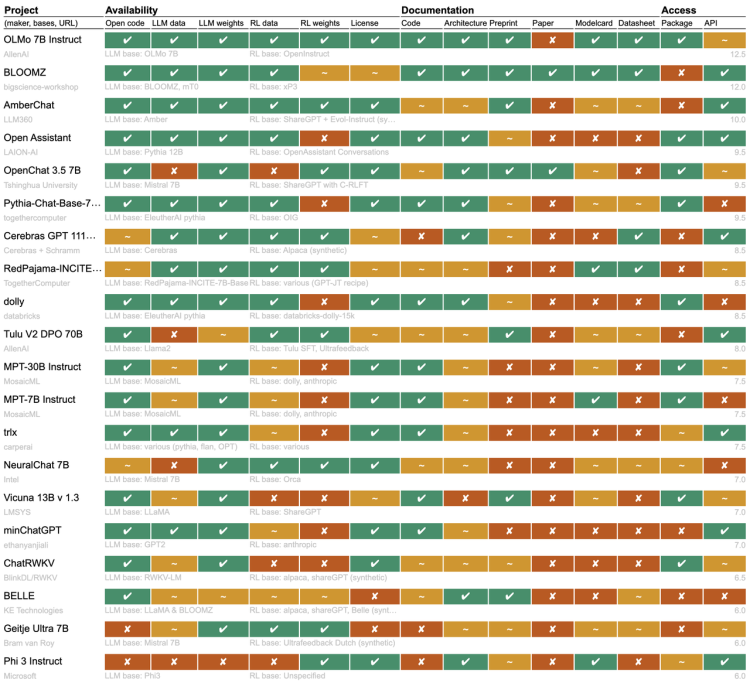
最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。 不过开源派和闭源派之间的争论并没有停下来的迹象。
最近两款大型 AI 模型相继发布。
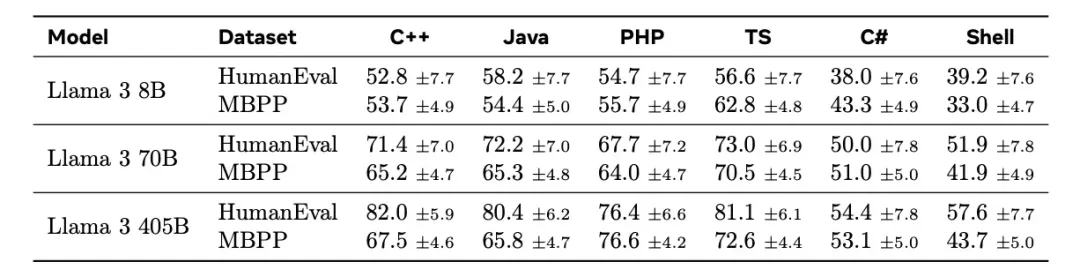
紧跟着Meta的重磅发布,Mistral Large 2也带着权重一起上新了,而且参数量仅为Llama 3.1 405B的三分之一。不仅在编码、数学和多语言等专业领域可与SOTA模型直接竞争,还支持单节点部署。

AI 竞赛正以前所未有的速度加速,继 Meta 昨天推出其新的开源 Llama 3.1 模型之后,法国 AI 初创公司 Mistral AI 也加入了竞争。

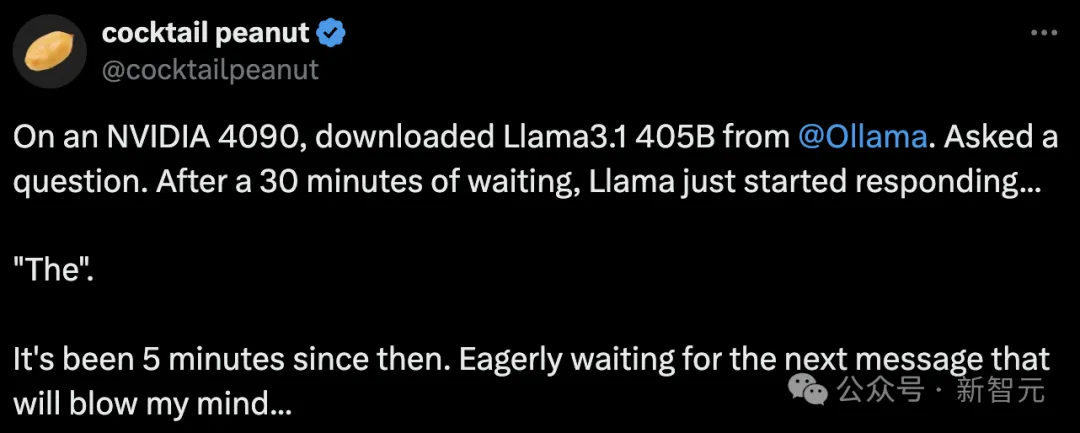
Llama 3.1 405B“最强模型”宝座还没捂热乎,就被砸场子了——