
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。
来自主题: AI技术研报
3791 点击 2024-07-26 17:57
 搜索
搜索
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。

MoE 因其在训推流程中低销高效的特点,近两年在大语言模型领域大放异彩。作为 MoE 的灵魂,专家如何能够发挥出最大的学习潜能,相关的研究与讨论层出不穷。此前,华为 GTS AI 计算 Lab 的研究团队提出了 LocMoE ,包括新颖的路由网络结构、辅助降低通信开销的本地性 loss 等,引发了广泛关注。

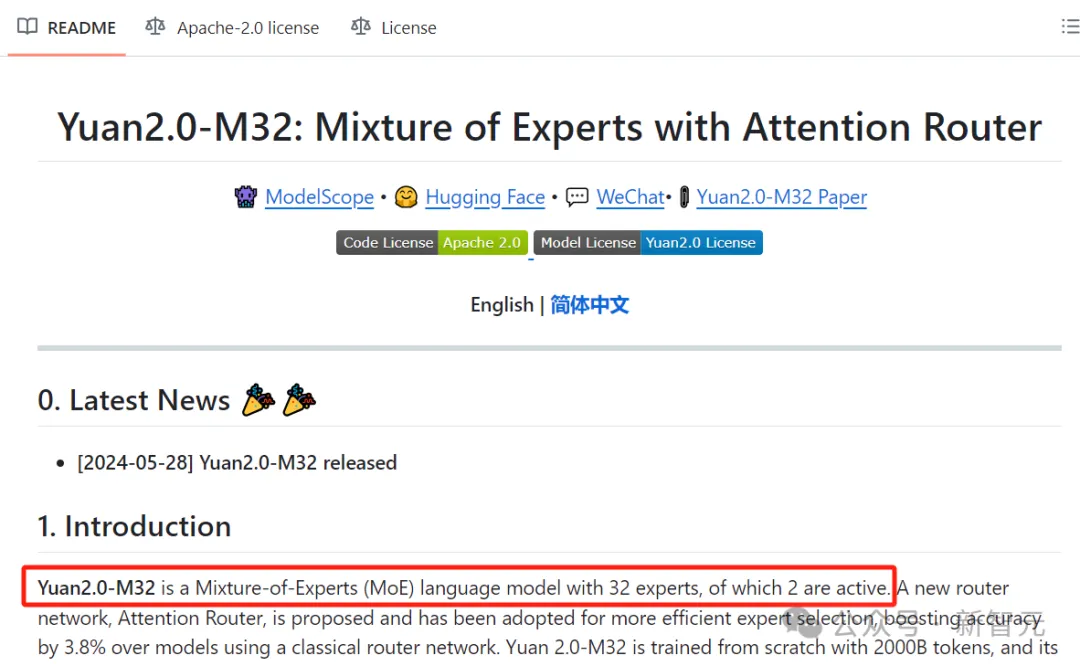
MoE已然成为AI界的主流架构,不论是开源Grok,还是闭源GPT-4,皆是其拥趸。然而,这些模型的专家,最大数量仅有32个。最近,谷歌DeepMind提出了全新的策略PEER,可将MoE扩展到百万个专家,还不会增加计算成本。

释放进一步扩展 Transformer 的潜力,同时还可以保持计算效率。

在今天揭幕的 2024 世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)上,阶跃星辰首发了三款 Step 系列通用大模型新品:Step-2 万亿参数语言大模型正式版、Step-1.5V 多模态大模型、Step-1X 图像生成大模型。

在 2024 年世界人工智能大会的现场,很多人在一个展台前排队,只为让 AI 大模型给自己在天庭「安排」一个差事。

在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。

每个token只需要5.28%的算力,精度就能全面对标Llama 3。
马斯克最近哭穷表示,xAI需要部署10万个H100才能训出Grok 3,影响全球的大模型算力荒怎么解?昨天开源的这款MoE大模型,只用了1/19算力、1/19激活参数,性能就直接全面对标Llama 3-70B!

前几天,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,论文提出构建完全可微的MoE模型,是一种预训练自回归语言模型的新方法。