
Attention Sink产生的起点?清华&美团首次揭秘MoE LLM中的超级专家机制
Attention Sink产生的起点?清华&美团首次揭秘MoE LLM中的超级专家机制稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
来自主题: AI技术研报
8404 点击 2025-08-12 11:07
 搜索
搜索
稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。

gpt5来临前夕,oai疑似发布的小模型gpt-oss 120B的架构图已经满天飞了。难得openai要open一次,自然调动了我的全部注意力机制。本来以为oai还要掏出gpt2意思意思,结果看到了一个120B moe。欸?!
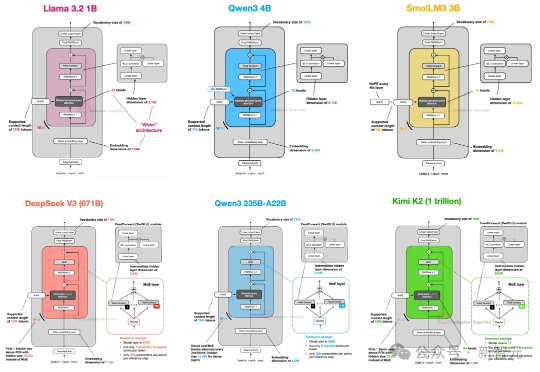
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。

电影级视频生成模型来了。
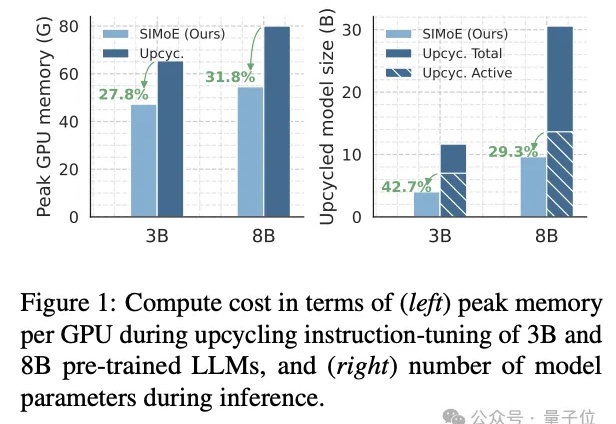
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
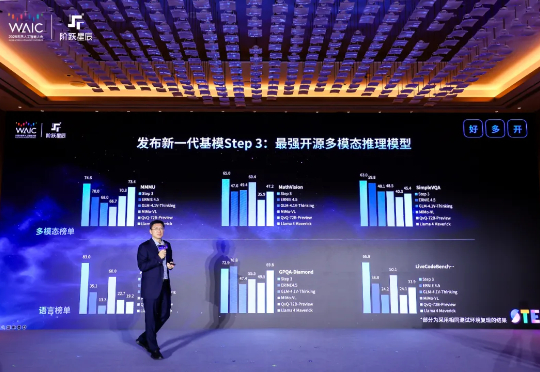
今天下午,阶跃星辰在 WAIC 2025 开幕前夕发布新一代基础大模型 Step 3,并宣布将在 7 月 31 日面向全球企业和开发者开源。MoE 架构,321B 总参,38B 激活

近日,月之暗面(Moonshot AI)正式发布了其万亿参数开源大模型Kimi K2,这一具有里程碑意义的AI模型凭借其创新的MoE架构和强大的Agentic能力迅速获得全球开发者关注。然而,随着用户量激增,部分开发者开始反映其API服务响应速度不尽如人意。面对这一情况,月之暗面于7月15日迅速作出官方回应,坦诚当前服务延迟问题,并详细说明了优化方案。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

结果点进去一看,我人直接傻了——这家伙用的竟然是 kimi-k2-0711-preview 模型!这个K2模型的简直离谱到家了: 业界第一个说自己是1万亿参数的模型,这规模直接吓人 MoE架构 + 32B激活参数

中国人民大学高瓴人工智能学院的研究团队提出通过创新模型架构来提升性能,其SPACE模型引入新架构,提升了DNA基础模型的性能与泛化能力,在多项测试中表现优异。