# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7 年前,谷歌在论文《Attention is All You Need》中提出了 Transformer。就在 Transformer 提出的第二年,谷歌又发布了 Universal Transformer(UT)。它的核心特征是通过跨层共享参数来实现深度循环,从而重新引入了 RNN 具有的循环表达能力。层共享使得 UT 在逻辑推理任务等组合问题上的表现优于 Transformer,同时还在小规模语言建模和翻译任务上得到改进。
UT 已被证明具有更好的组合泛化特性,能够在无监督的情况下解构结构化问题并泛化到更长的序列。因此与 Transformer 相比,UT 是一种具有卓越泛化特性的通用性更强的架构。
但 UT 的计算效率远低于标准 Transformer,不适合当前语言建模等以参数为王的任务。那么,我们能不能开发出计算效率更高的 UT 模型,并这类任务上实现比标准 Transformer 更具竞争力的性能呢?
近日,包括 LSTM 之父 Jürgen Schmidhuber、斯坦福大学教授 Christopher Manning 等在内的研究者从全新视角出发,提出了解决 UT 基础计算参数比问题的最新方案。具体来讲,他们提出 Mixture-of-Experts Universal Transformers(简称 MoEUT),它是一种混合专家(MoE)架构,允许 UT 以计算和内存高效的方式扩展。

在文中,研究者利用了 MoE 在前馈和自注意力层方面的各种最新进展,并将这些进展与以下两项创新工作相结合:1)layer grouping,循环堆叠 MoE 层组;2)peri-layernorm 方案(位于 pre-layernorm 和 post-layernorm 之间),并且仅在紧接 sigmoid 或 softmax 激活之前应用层范数。这两者都是专为共享层 MoE 架构设计,并且有强有力的实证证据支持。
从其作用来讲,MoEUT 允许构建参数和资源高效的 UT 语言模型,不仅在我们可以负担得起的所有规模(最高 10 亿参数)上对算力和内存的需求更低,性能也超越了标准 Transformer。
研究者在 C4、SlimPajama 和 peS2o 语言建模数据集、以及 The Stack 代码数据集上测试 MoEUT 的能力,结果表明,循环对于模型实现具有竞争力的性能至关重要。同样地,研究者在 BLiMP 和儿童图书测试、Lambada、HellaSwag、PIQA 和 ARC-E 等下游任务上展现了良好的零样本性能。
如前文所述,MoEUT 是一种具有层共享参数的 Transformer 架构,其中使用 MoE 来解决参数计算比问题。虽然最近出现了很多关于 Transformer 语言模型的 MoE 方法研究,但要让它们在参数相同的情况下与密集方法竞争,仍然是一项艰巨的任务。
因此,研究者利用了 MoE 前馈网络块(FFN)、MoE 自注意力层,并引入了两种考虑到共享层模型特定属性的新方法 ——layer grouping 和信号传播。这些技术的结合对于实现有效的共享层 MoE Transformer 发挥了巨大作用。

在每个 token 位置 t,给定层输入 x_t ∈ R^d_model,MoE 前馈层会为每个专家计算一个分数,从而得到一个向量 s ∈ R^N_E,其计算如下:

MoE 层仅选择与 s_t ∈ R^N_E 中 top-K 元素相对应的 K 个专家(从 N_E 中),来产生层输出 y_t ∈ R^d_model,如下所示:
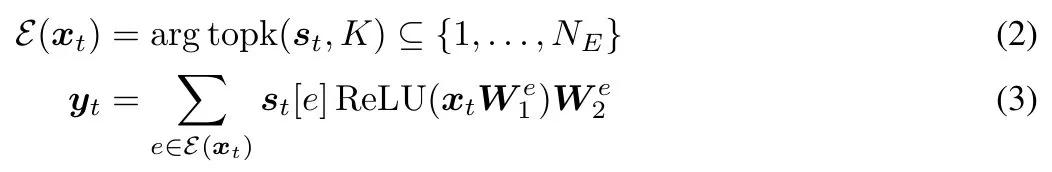
初步实验表明,σ-MoE 的原始正则化往往不稳定,有时会导致训练期间损失激增。为了避免这种情况,研究者仅在序列内应用正则化(而不是批次中的所有 token)。对于输入序列 x_t,t ∈ {1,...,T},计算平衡损失 L 如下所示:

为了将 MoE 引入自注意力层,研究者应用了 SwitchHead,它是一种将 σ-MoE 扩展到注意力层的 MoE 方法。与标准多头注意力层一样,SwitchHead 层中的每个头包含四个转换:查询、键、值和输出投影。但是,SwitchHead 使用 MoE 来参数化值和输出投影。
也即,每个头都有一个与之关联的查询和键投影以及 N_A 值和输出投影,它们针对每个输入进行动态选择。
键和查询「照常」计算:给定位置 t 处的一个输入,x_t ∈ R^d_model,并且 k^h_t = x_tW^h_K、q^h_t = x_tW^h_Q,h ∈{1,...,H} 是头索引。专家对这些值的选择计算如下:
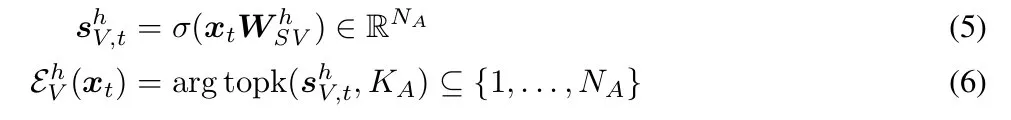

研究者观察到,基于 MoE 的原始 UT 只有一个共享层,在更大规模上往往难以获得良好的性能。假设原因有二:首先,随着网络规模的扩大,层中专家的数量会迅速增加,但我们无法以相同的速度增加活跃专家 K 数量而不大幅增加所需计算量。这就迫使我们降低活跃专家的比例,而这通常是不利的。其次,注意力头的总数保持在相对较低的水平,这对于一个大型模型来说可能是不够的。增加注意力头的数量也同样代价高昂。
因此,在增加注意力头总数的同时,可以调用一组层,减少每个 σ-MoE 中的专家数量。最终的网络是通过重复堆叠这些共享相同参数的小组而得到的(从某种意义上说,将组重新定义为 UT 中的共享层)。
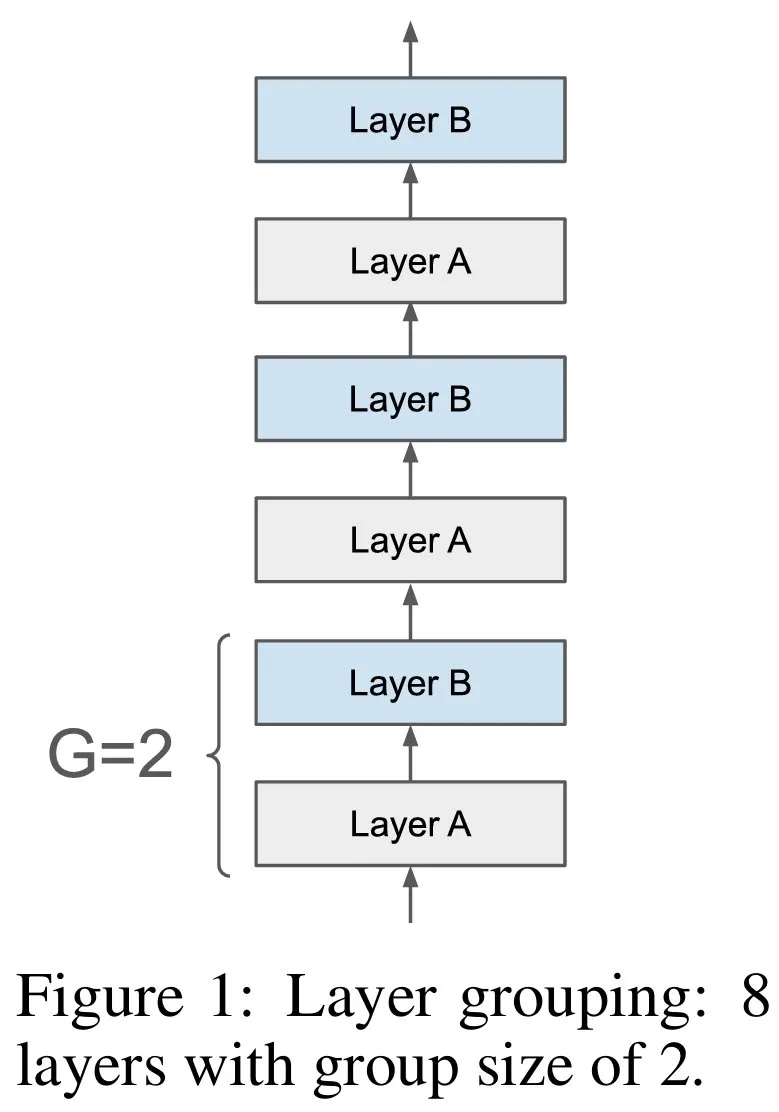
下图 1 提供了一个示例,标记为「层 A」(或层 B)的所有层在整个网络中共享相同的参数。组 G 的大小是非共享层的数量。在研究者的实验中,组大小在 2 到 4 之间,典型的循环步骤数为 8 或 9。
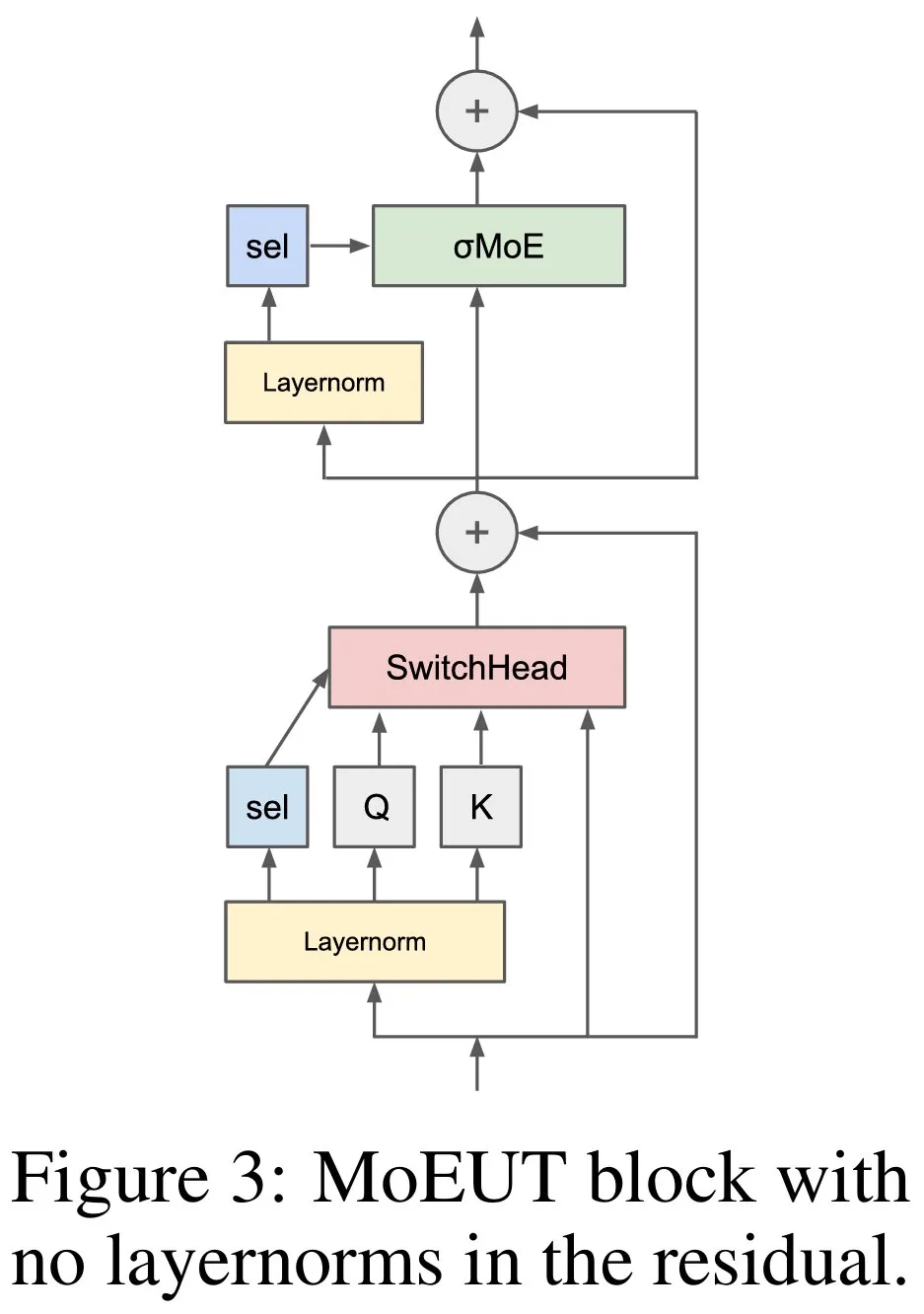
研究者提出另一种方法来避免上述问题:在「主数据路径」中不使用分层归一化。这意味着,对于本文的 UT,在注意力值投影之前不使用分层矩阵,在 σ-MoE 层之前也不使用分层矩阵。相反,只有在紧跟着 sigmoid 或 softmax 激活函数的线性层(在这些非线性层之前产生关键的重归一化激活)之前,即注意力中的查询和关键投影、注意力层和前馈层上的专家选择以及最终分类层之前,才会使用 layernorm。如图 3 所示。
由于前馈层内的主数据路径上只使用了 ReLU 激活函数,因此输出更新将与输入成正比,从而有效地解决了残差增长问题,同时也提供了高效的梯度流路径。这种方案称为 「peri-layernorm」方案,它介于「pre-layernorm」和「post-layernorm」方案之间,将 layernorm 定位在残差连接的「周围」(但不在其上)。具体如下图 3 所示。
在论文中,研究者展示了使用流行的 C4 数据集进行语言建模时 MoEUT 性能和效率的主要实验结果。为了证明 MoEUT 的通用性,研究者还展示了在 SlimPajama 和 peS2o 语言建模数据集上的主要结果,以及在 「The Stack」上的代码生成。
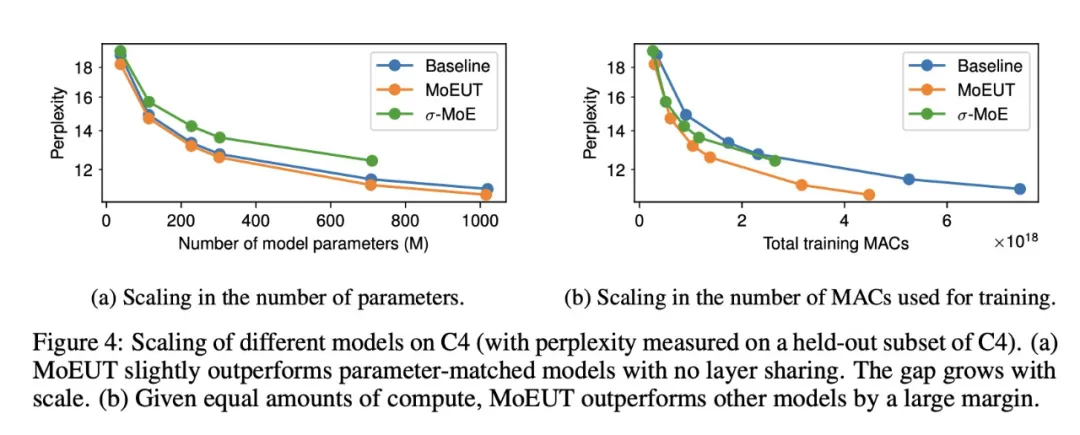
MoEUT 的 Scaling 结果如图 4 所示。y 轴显示的是 C4 held-out 子集上的复杂度。在参数数量相同的情况下,MoEUT 模型略微优于密集模型(图 4a),而且随着规模的扩大,差距呈扩大趋势。研究者还与非共享 σ-MoE 模型进行了比较,该模型的表现明显不如 MoEUT,这表明共享层具有明显的优势。此外如图 4b 显示,就训练期间所有前向传递所花费的总 MAC 运算次数而言,MoEUT 远远优于基线密集模型。
代码生成性能
为了证实 MoEUT 在不同任务领域的有效性,研究者在「The Stack」数据集的一个子集上对其进行了训练,该数据集是一个代码生成任务。由于无法进行完整的 epoch 训练,因此这里只使用了几种语言并混合使用了这些语言:Python、HTML、C++、Rust、JavaScript、Haskell、Scala 和汇编。研究者在数据集的一个 held-out 子集上评估了 MoEUT。结果如图 5 所示,与自然语言领域的结果一致:MoEUT 的表现优于基线。
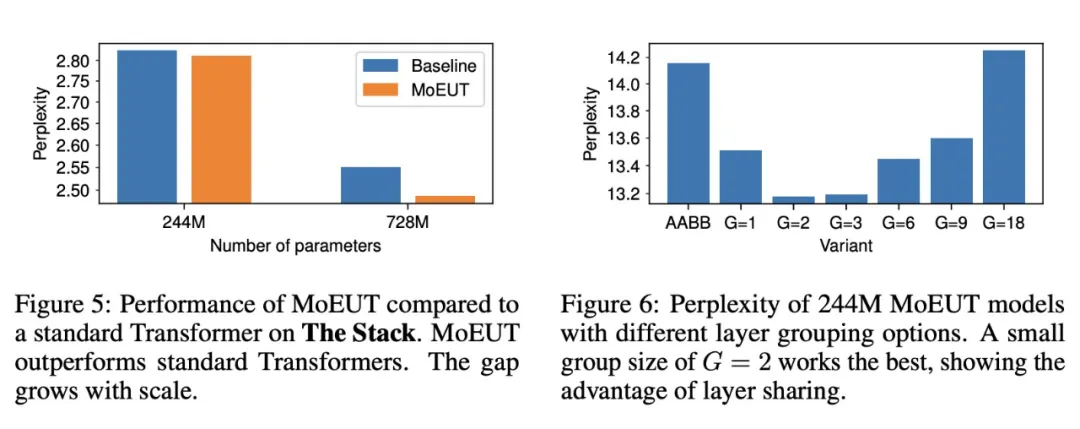
图 6 展示了 layer grouping 对 244M 参数 MoEUT 模型的影响。研究者发现 G = 2 是最佳值,而且层维度的循环确实是有益的。
下游任务上的零样本表现
研究者评估了 MoEUT 在六个不同下游任务中的零样本性能:LAMBADA、BLiMP、Children's Book Test (CBT) 、HellaSwag、PIQA 和 ARC-E。结果见表 1,MoEUT 的表现往往优于基线,但在所有情况下差异都很小。
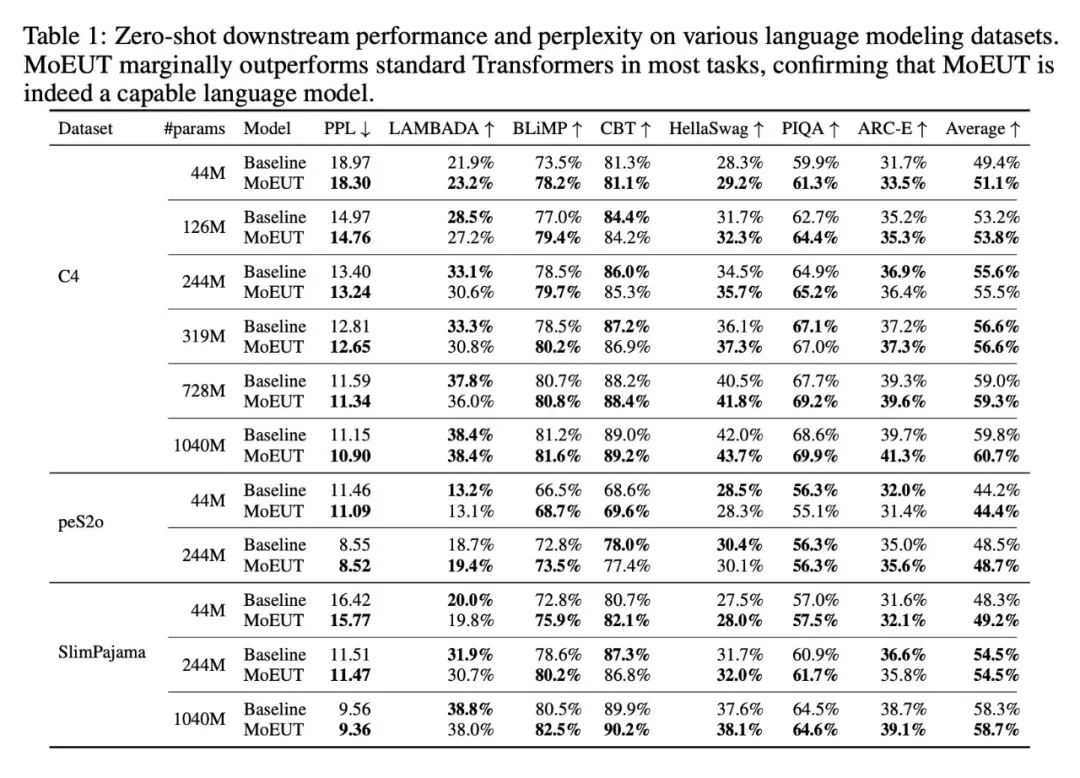
研究者还将 MoEUT 与另一个基准模型 Sparse Universal Transformer(SUT)进行了比较,SUT 是最近提出的一个 UT 模型,也使用了 MoE 层,且以前未在标准语言建模任务中进行过评估。虽然 MoEUT 和 SUT 都在前馈层和注意力层使用了 MoE,但这两种方法在不同层面上存在一些技术差异:SUT 使用竞争性专家选择(softmax)、多重负载平衡损失和更大的专家规模,且采用 post-layernorm 模式,不使用 layer grouping。与 MoEUT 的方法不同,SUT 在层维度上使用了自适应计算时间(ACT)。
结果如图 7 所示。与 MoEUT 和参数匹配的密集基线相比, SUT 在性能上有明显的劣势。研究者认为这种性能低下的主要原因是作者将 ACT 机制作为其模型的主要组成部分之一。移除 ACT 后,性能显著提高。然而,即使在这种设置下,它的性能仍然低于 MoEUT 和标准 Transformer 基线。
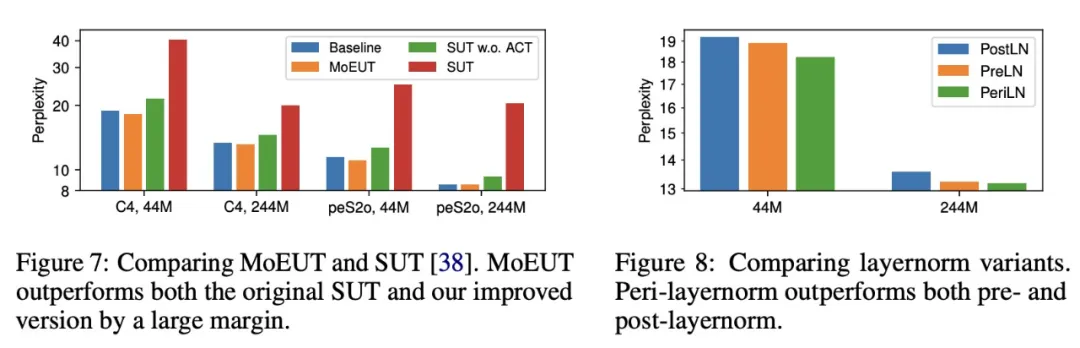
研究者还对「peri - 层归一化」进行了评估。图 8 显示了结果。本文的层归一化方案始终表现最佳。小模型的差距更大,而大模型的差距则越来越小(对于 719M 参数模型,peri-norm 和 post-norm 之间的差距微乎其微)。同时,随着训练步数的增加,peri-norm 和 post-norm 之间的差距也在增大,因此如果模型的训练时间更长,就有可能获得更高的收益。
为了更好地理解 MoEUT 的专家选择,研究者分析了在 C4 上训练的 244M 参数 MoEUT 模型的 MLP 块中的专家选择。本节中的所有实验都是通过计算 C4 验证集上 G = 2(即模型组中有两层)模型的统计数据进行的。这里只展示了模型组第一层的行为,因为研究者发现第二层的结果在本质上是相似的。
结果表明,MoEUT 能够根据不同情况动态调整其专家选择机制。有时,专家会被分配给流行的 token,而在其他情况下,专家会在各层之间共享或专门化,这取决于哪种方式更适合任务。
专家的跨层使用。如图 9 所示,右下角的黄点表示一些专家主要被分配到最后一层。然而,对于其他专家来说,专家被激活的层范围很广。专家似乎是在连续的层序列中被激活的,这可以从纵向排列的宽阔结构中看出。因此可以得出这样的结论:如果有必要,MoEUT 能够专注于特定层,并可在各层之间共享权重。
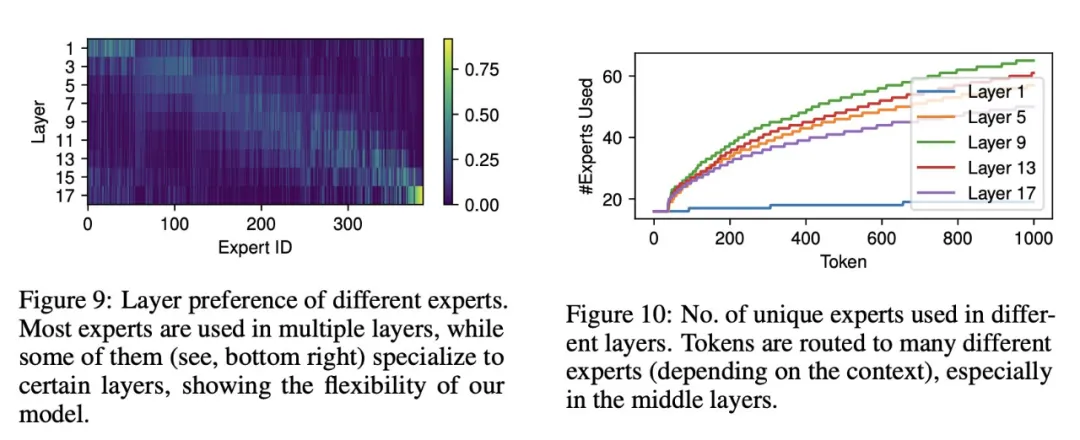
每个 token 专家选择的多样性。研究者分析了 MLP 各层针对给定输入 token 在不同层和上下文中的专家选择多样性。为此,他们测量了不同层在不同位置 / 上下文下为单个 token 激活的专家总数。结果如图 10 所示。
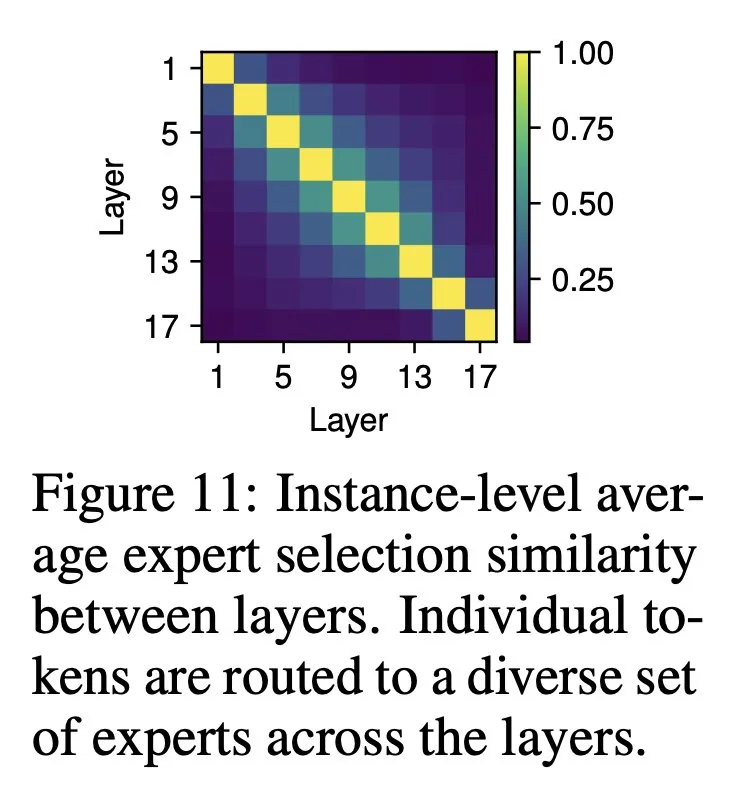
各栏/位置的专家选择动态。结果如图 11 ,在后续层中,所选专家之间存在不可忽略的重叠;但是,这种重叠还远远没有达到完全重叠的程度。这表明,专家通常在单列中动态变化,在不同层中执行不同的功能。
文章来自于“机器之心”,作者“杜伟、蛋酱”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
