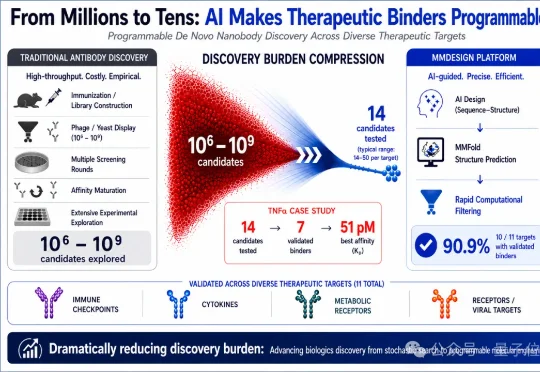
AI生物研发进入“操作系统时代”,许锦波团队MoleculeOS正式开放
AI生物研发进入“操作系统时代”,许锦波团队MoleculeOS正式开放在2026上海国投前沿论坛上,分子之心创始人许锦波教授正式面向产业界开放其自研的AI原生生物经济操作系统——MoleculeOS(MOS)。在这里,AI的角色从生物规律的“预测者”,蜕变为研发流程的“组织者”。
来自主题: AI资讯
7560 点击 2026-07-11 11:18
 搜索
搜索
在2026上海国投前沿论坛上,分子之心创始人许锦波教授正式面向产业界开放其自研的AI原生生物经济操作系统——MoleculeOS(MOS)。在这里,AI的角色从生物规律的“预测者”,蜕变为研发流程的“组织者”。

论文将汇总人类从出生到死亡每个神经元的活动情况。利用更完善的“分子记录带”(molecular ticker tape)技术,神经元每发出一个电脉冲,都会在其蛋白链上加上一段荧光分子。通过对这些蛋白链进行测序,可以获得神经元整个生命周期内神经活动的完整历史记录。同时对每个神经元的mRNA进行测序,可以确定它属于10.4万个神经元类型中的哪一种。
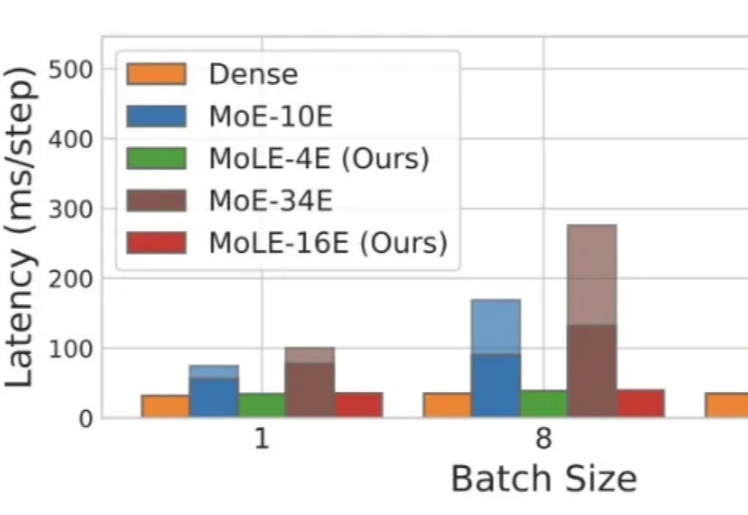
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。