
独家:Kimi悄悄发布了全球首个参数量达到1万亿的K2模型
独家:Kimi悄悄发布了全球首个参数量达到1万亿的K2模型结果点进去一看,我人直接傻了——这家伙用的竟然是 kimi-k2-0711-preview 模型!这个K2模型的简直离谱到家了: 业界第一个说自己是1万亿参数的模型,这规模直接吓人 MoE架构 + 32B激活参数
来自主题: AI资讯
11162 点击 2025-07-11 18:38
 搜索
搜索
结果点进去一看,我人直接傻了——这家伙用的竟然是 kimi-k2-0711-preview 模型!这个K2模型的简直离谱到家了: 业界第一个说自己是1万亿参数的模型,这规模直接吓人 MoE架构 + 32B激活参数

中国人民大学高瓴人工智能学院的研究团队提出通过创新模型架构来提升性能,其SPACE模型引入新架构,提升了DNA基础模型的性能与泛化能力,在多项测试中表现优异。

7月5日下午16:59分,隶属于华为的负责开发盘古大模型的诺亚方舟实验室发布声明对于“抄袭”指控进行了官方回应。诺亚方舟实验室表示,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型
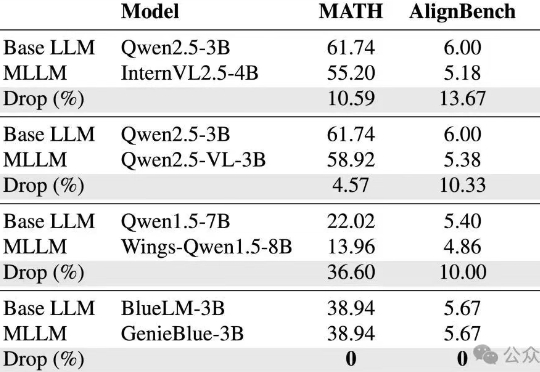
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。

混合专家网络模型架构(MoE)已经成为当前大模型的一个主流架构选择,以最近开源的盘古Pro MoE为例

超大规模MoE模型(如DeepSeek),到底该怎么推理才能做到又快又稳。现在,这个问题似乎已经有了标准答案——华为一个新项目,直接把推理超大规模MoE背后的架构、技术和代码,统统给开源了!

刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。
6 月 27 日,腾讯混元宣布开源首个混合推理 MoE 模型 Hunyuan-A13B,总参数 80B,激活参数仅 13B,效果比肩同等架构领先开源模型,但是推理速度更快,性价比更高。模型已经在 Github 和 Huggingface 等开源社区上线,同时模型 API 也在腾讯云官网正式上线,支持快速接入部署。

最近,华为在MoE训练系统方面,给出了MoE训练算子和内存优化新方案:三大核心算子全面提速,系统吞吐再提20%,Selective R/S实现内存节省70%。

现在,请大家一起数一下“1”、“2”。OK,短短2秒钟时间,一个准万亿MoE大模型就已经吃透如何解一道高等数学大题了!而且啊,这个大模型还是不用GPU来训练,全流程都是大写的“国产”的那种。