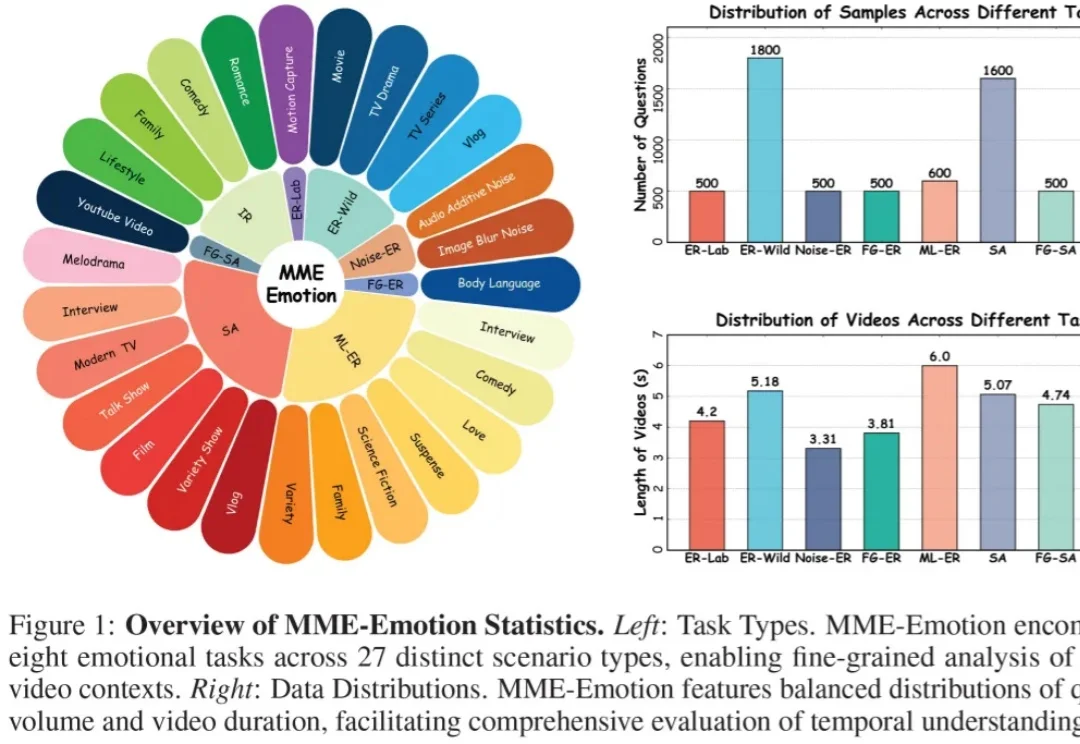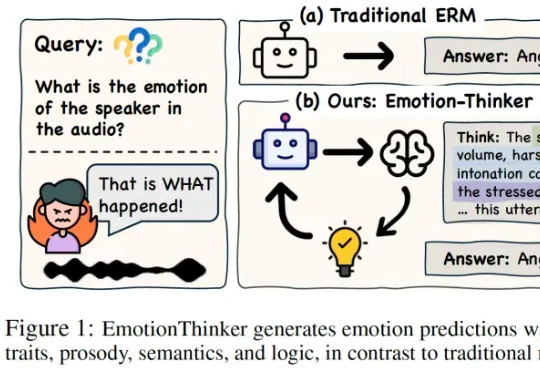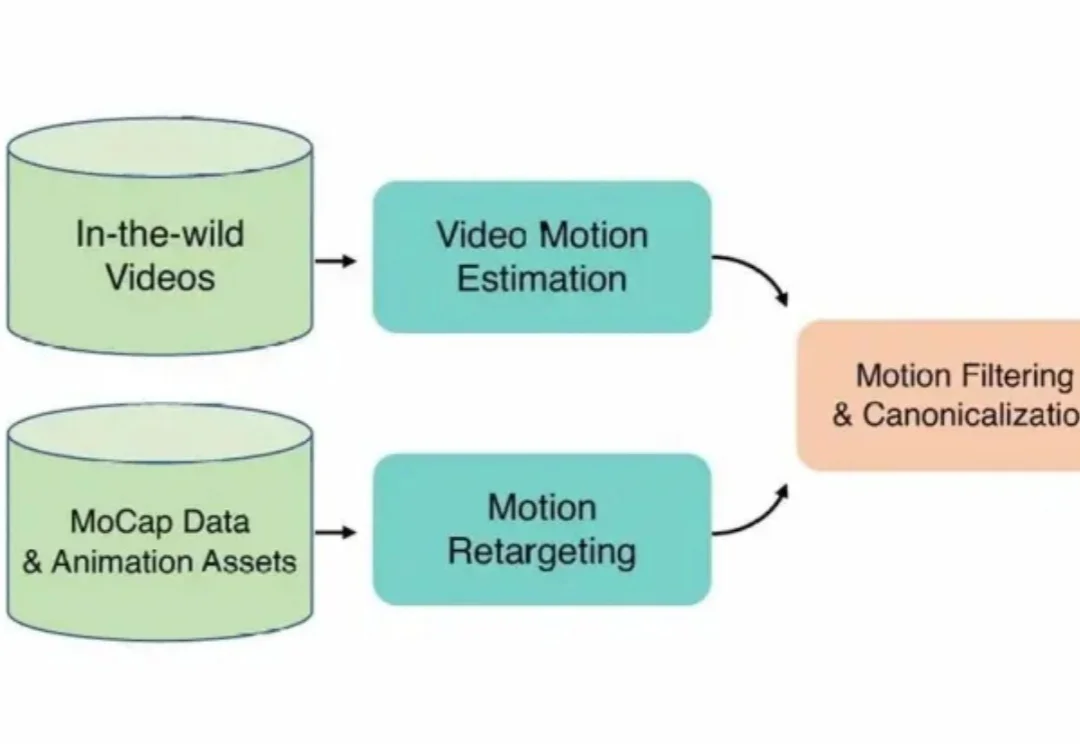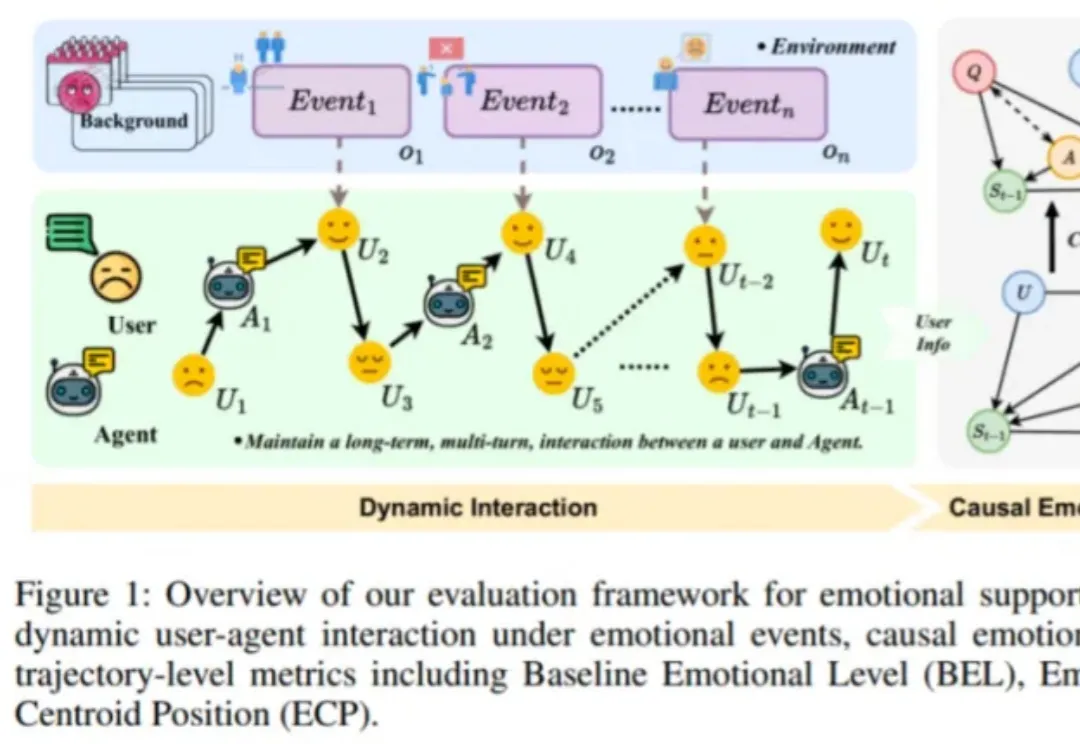
CVPR 2026 | BiMotion:用 B 样条曲线重新定义 3D 角色运动生成
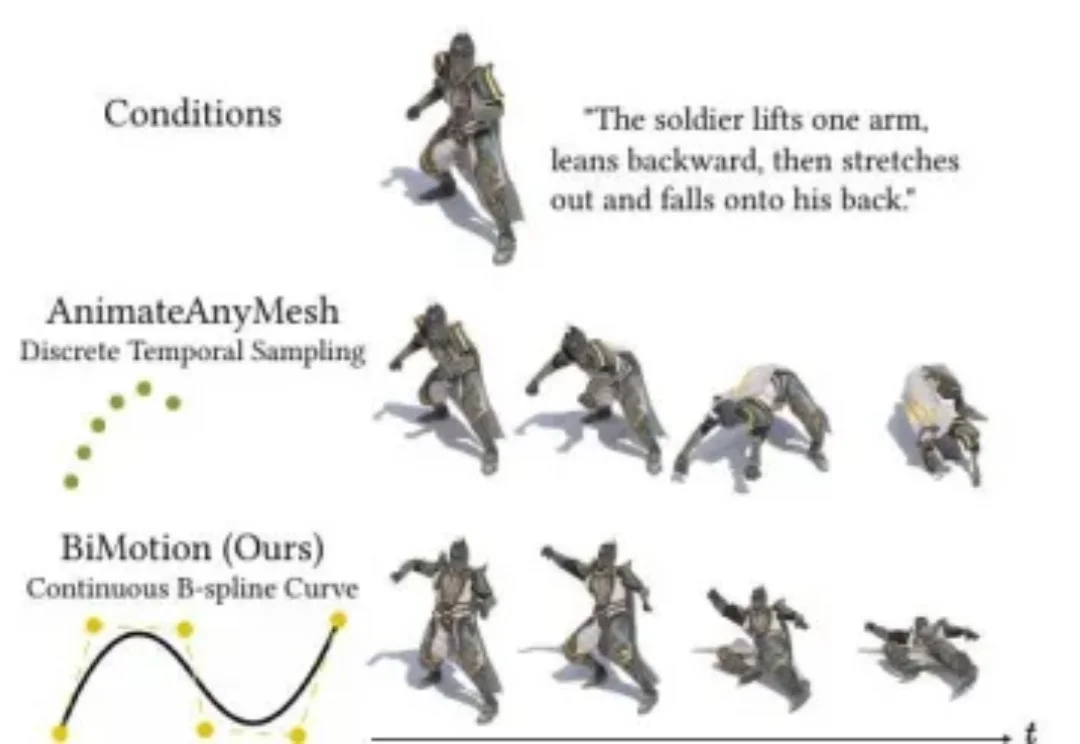
CVPR 2026 | BiMotion:用 B 样条曲线重新定义 3D 角色运动生成当你希望 AI 将 "士兵举起手臂,向后倾身,然后身体向前扑倒" 这段文字转化为一段 3D 角色动画,现有大多数方法给出的答案是:一段摇摇晃晃、语义残缺的短片段。这并非模型能力不足,问题的根源在于将运动表达为逐帧离散序列这一根本性的设计决策。
来自主题: AI技术研报
6864 点击 2026-03-30 09:28