邢波再出手:上次「骂」完世界模型,这次轮到智能体了
邢波再出手:上次「骂」完世界模型,这次轮到智能体了去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
来自主题: AI技术研报
7187 点击 2026-07-01 15:43
 搜索
搜索
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
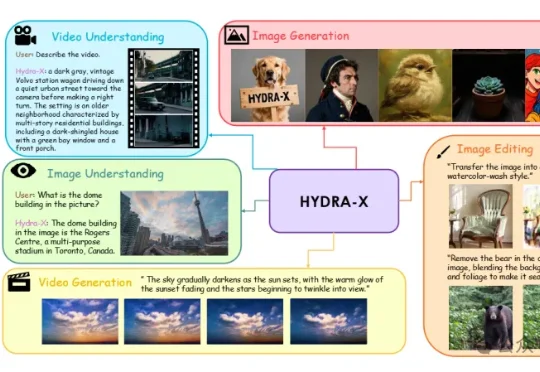
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。
国产算力生态的难题,从此有了 AI 解。

《读佳》从读者处获悉:我们此前独家曝光的蚂蚁集团新产品Qmuse已经上线,并开始内测,目前支付宝账号是唯一登录方式。该产品由蚂蚁数智信息技术(上海)有限公司(下称“蚂蚁数智”)所有及运营。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。