# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
Transformer「杀手」架构迎重磅升级!
就在今天,Mamba架构的「原班人马」正式发布了最新一代开源架构——Mamba-3。

论文地址:https://arxiv.org/pdf/2603.15569
与Mamba-2相比,Mamba-3对核心SSM做了三大改动:


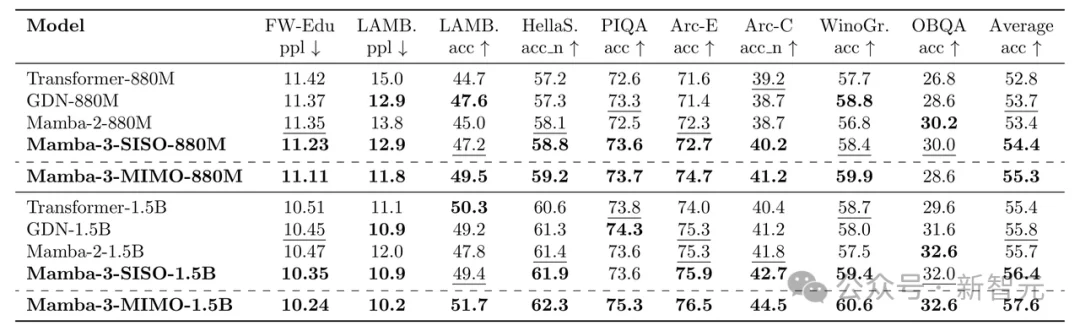
结果证明,仅用一半的内部状态大小,Mamba-3实力便与Mamba-2相当。
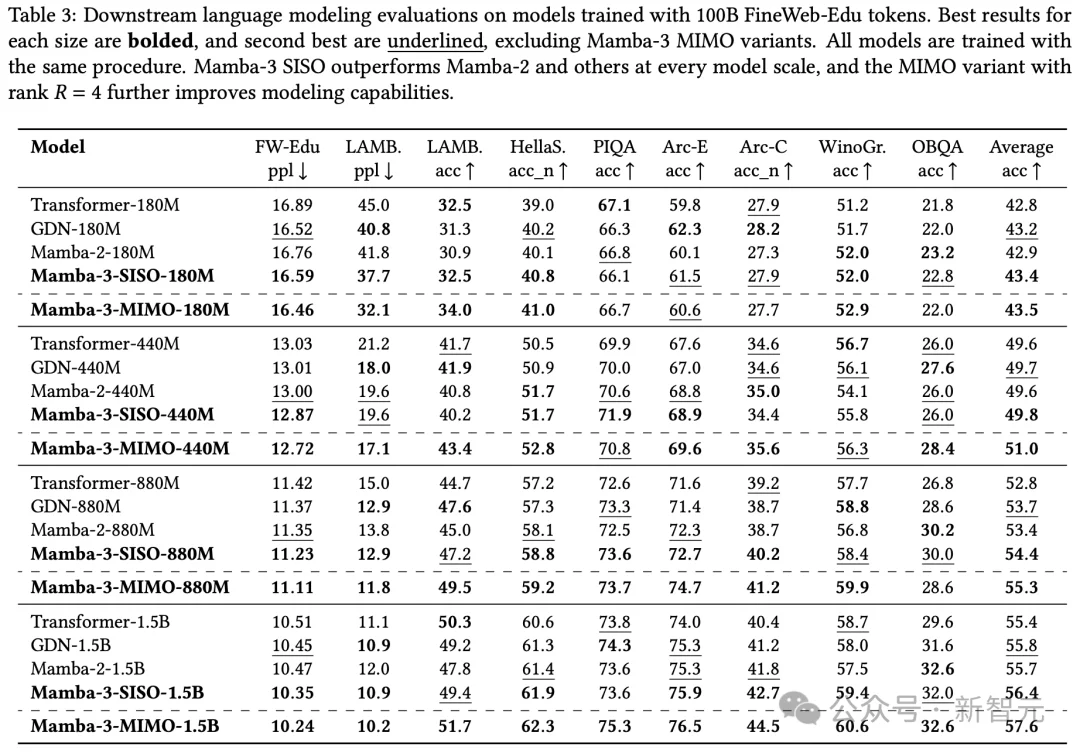
在15亿参数规模下,Mamba-3 MIMO版本的平均准确率达到57.6%,比Transformer高出4%。
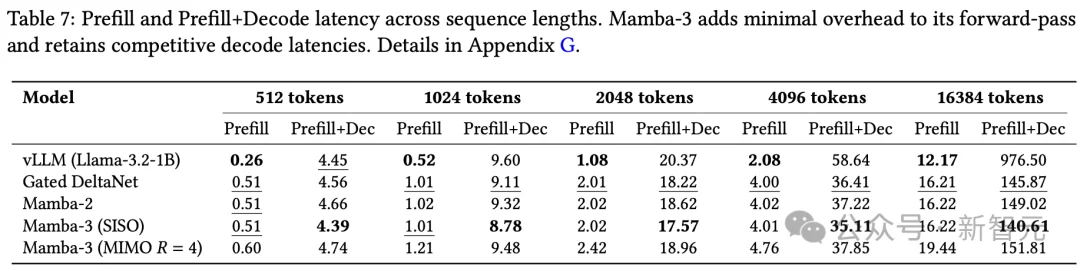
在长序列任务上,Mamba-3的端到端延迟仅为Transformer的七分之一。
2017年,Transformer架构横空出世,成为当今LLM的基石。
然而,它是一个不折不扣的「算力黑洞」,随着对话长度增加,计算需求呈平方级增长,内存占用线性飙升,导致大规模推理成本极高。
为打破这一僵局,2023年,首个Mamba架构应运而生。
2024年中,Mamba-2发布,进一步打通了SSM与注意力机制之间的数学等价关系,训练速度提升2-8倍。

如今,由Albert Gu和Tri Dao联合指导、四位学生研究员主力操刀的Mamba-3,带着全新设计哲学登场。
Mamba-3代表着一种范式转移:从追求训练效率,转向「推理优先」的设计。
正如Albert Gu所说,Mamba-2的重点是打破预训练的瓶颈,Mamba-3则是为了解决「冷GPU」问题——
即在解码过程中,现代硬件往往是在干等着数据传输(内存移动),而不是在真正进行计算。
高效秘籍:摘要机器
作为一种状态空间模型(SSM),Mamba-3就像一个高效的「摘要机器」。
其核心逻辑与Transformer有本质区别。
Transformer每生成一个词,都要回顾全部历史token来理解上下文,历史越长负担越重。
而Mamba-3将历史信息实时压缩成一个固定大小的「内部状态」,你可以理解为数据历史的「快照」。
每当新信息进入,架构只需更新快照而无需重读全文。这就是SSM能做到固定内存、线性计算的根本原因。
对SSM来说,这个「快照」的大小(即状态大小)是决定性能的核心旋钮:
状态越大,能压缩的信息越丰富,模型越聪明,但推理时搬运数据的开销也越大,速度就越慢。
反过来,状态缩小一半,速度能快一倍,但模型可能会变笨。
Mamba-3的突破就在这里。它用仅为Mamba-2一半的状态大小,达到了与Mamba-2相当的语言建模性能。
聪明程度不变,速度翻倍——等于把SSM的性能-效率曲线整体往下推了一档。
Mamba-3是怎么做到的?这背后是一套全新的设计哲学:重新思考AI的「智能」与运行它的硬件速度之间的关系。
如果说Mamba-2是为了刷训练速度的记录,那么Mamba-3就是一种「推理优先」的架构。
所谓推理,就是用户在ChatGPT、Gemini或通过API使用AI的过程。
Mamba-3的核心目标是榨干GPU活跃的每一秒钟,确保模型在不让用户等待的情况下,进行最密集的「思考」。
围绕这个目标,Mamba-3祭出了三招——
接下来逐一拆解。
三大核心技术
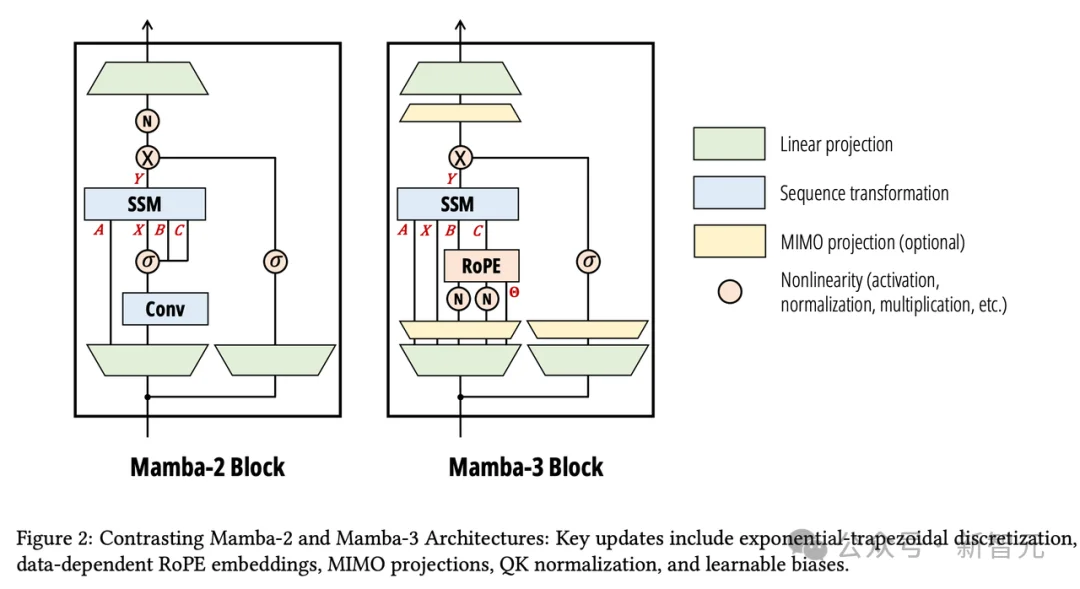
Mamba-1和Mamba-2使用的离散化方法,本质上是一阶近似,类似于用一个端点的高度来估算一段曲线下的面积。
Mamba-3升级为「指数梯形法则」,同时参考两个端点进行加权平均,精度从一阶跃升到二阶。
这看似只是数学层面的微调,效果却出乎意料。
它在SSM的状态输入上隐式引入了一个宽度为2的数据依赖卷积,直接让Mamba-2中必不可少的短因果卷积模块变成了可选项。
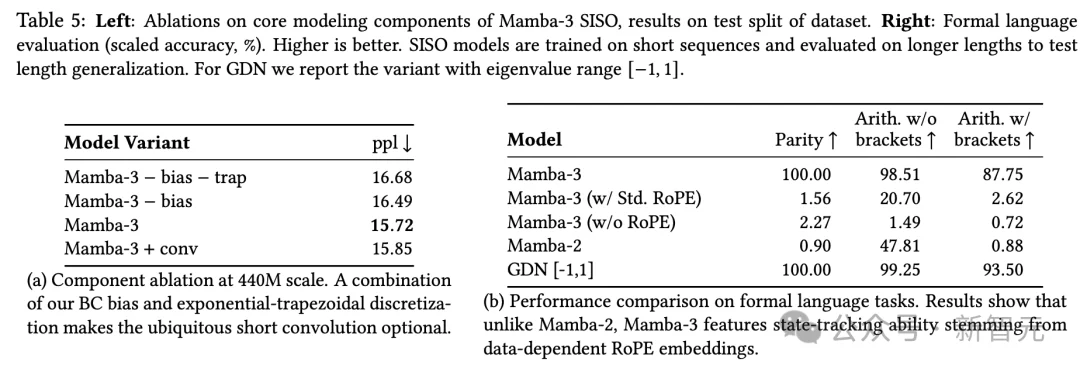
消融实验显示,指数梯形离散化与B、C偏置项的组合,能够完全替代过去几乎所有线性模型都依赖的外部短卷积——这是架构简化的重要一步。
长期以来,Transformer的替代方案都有一个「逻辑短板」——在简单的状态追踪任务(比如判断二进制序列的奇偶性)中经常翻车。
根本原因在于,Mamba-2将状态转移矩阵限制为实数标量,无法表达「旋转」动态。
举一个直观的例子,奇偶校验本质上是一个翻转操作——每读入一个1,状态就翻转一次。这种翻转在数学上对应旋转,而实数域天然不支持旋转。
Mamba-3通过引入复数值状态空间解决了这个问题。
结果证明,离散化后的复数SSM,等价于在B、C投影上施加一种数据依赖的旋转位置嵌入(RoPE)。
这意味着可以用高效的「RoPE技巧」来实现复数运算,计算开销几乎可以忽略。
数据显示,在奇偶校验任务上,Mamba-3达到100%准确率,而Mamba-2只有0.9%,和随机猜测无异。
在模算术任务上,Mamba-3同样达到98.51%,Mamba-2仅47.81%。线性模型的推理能力终于能和最先进的系统平起平坐。
现在的AI模型大多受限于「内存带宽」。
一组数据足以说明问题:Mamba标准SISO解码的算术强度仅约2.5 ops/byte,而NVIDIA H100的bf16张量核心能力是295 ops/byte。
换算下来,GPU在解码时有超过99%的计算能力在空转。

Mamba-3引入多输入多输出(MIMO)公式,将状态更新从外积运算变成矩阵乘法。
当MIMO秩为4时,每一步的计算量增加到原来的4倍,但由于这些计算恰好填满了空闲的张量核心,解码延迟几乎没有增加。
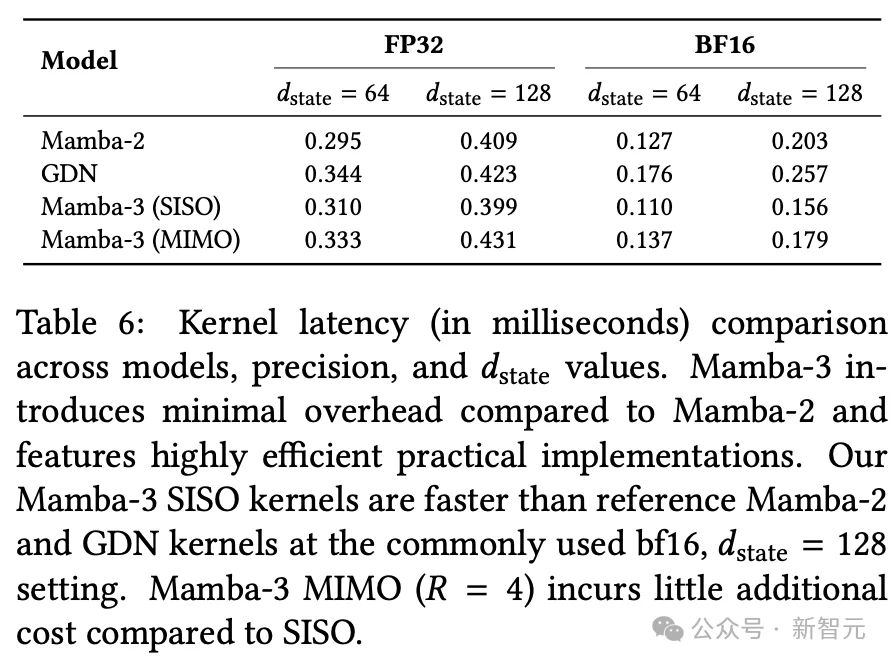
kernel延迟测试验证了这一点。在bf16、状态维度128的常用配置下,Mamba-3 SISO解码延迟仅0.156毫秒,比Mamba-2(0.203毫秒)还快;MIMO版本为0.179毫秒,依然快于Mamba-2。
用一句话总结MIMO的哲学:不是让GPU跑得更快,而是不让它闲着。
研究团队在4个参数规模(180M、440M、880M、1.5B)上进行了系统对比,对手包括Transformer、Mamba-2和Gated DeltaNet(GDN)三大基线。
所有模型使用相同的训练流程、100B FineWeb-Edu数据、Llama-3.1分词器。
在1.5B规模下,Mamba-3 MIMO以57.6%的平均准确率排名第一,领先Transformer 4%、Mamba-2 3.4%、GDN 3.2%。
即使是不使用MIMO的标准版Mamba-3 SISO,也以56.4%超越了所有非Mamba-3基线。
在端到端推理延迟上,16384个token的prefill+decode场景中,Mamba-3 SISO耗时140.61秒,而vLLM跑Llama-3.2-1B需要976.50秒,快了近7倍。
随着序列长度增长,线性模型的优势只会越来越大。
更值得关注的是上下文长度外推能力。所有模型仅在2K长度上训练,然后直接扔到更长的序列上测试。
结果显示,Mamba-3的语言建模表现一路稳步提升直到32K,而Mamba-2在超过训练长度后迅速崩坏。
这说明Mamba-3不仅在训练分布内更强,面对从未见过的长序列时也更加稳健。
不过,Mamba-3团队对一个现实问题并不回避:纯SSM模型在检索任务上仍不如Transformer。
这很好理解。固定大小的状态就像一个容量有限的笔记本,而Transformer的KV缓存是一个可以无限扩展的档案柜。需要精确回忆「第三段第二句话说了什么」时,档案柜天然更占优。
他们的解法是混合架构:将Mamba-3层与无位置编码的自注意力层按5:1比例交替堆叠。
实验显示,这种混合模型在检索任务上超过了纯Transformer基线,同时保持了线性模型的高效推理能力。
这也印证了行业趋势,Nemotron-H、Kimi Linear、HunyuanTurboS都在走混合路线,把Mamba层和注意力层穿插组合。
未来最有竞争力的模型架构,大概率不是「非此即彼」,而是「各取所长」。
这次Mamba-3的一个突出特点是「学生主导」。
正如Gu在发布推文中写道:「这是第一个由学生主导的Mamba,所有功劳归于他们。」

Kevin Li是卡内基梅隆大学机器学习系的博三在读生。
在此之前,他在佐治亚理工学院完成了计算机科学和生物医学工程的本科课程,导师是Polo Chau教授。
个人研究兴趣主要集中在开发高效的深度学习架构与方法,以及通过扩展推理端算力来提升模型的逻辑推理能力和通用性能。

Berlin Chen目前是普林斯顿大学计算机科学博士生,也是Together AI实习生。
此前,他曾获得了剑桥大学数学硕士学位,斯沃斯莫尔学院 (Swarthmore College)的数学与计算机科学学士学位。

Caitlin Wang目前是普林斯顿大学计算机科学专业的大学生。
共同指导者之一的Tri Dao,越南裔美国人,斯坦福博士毕业后加入普林斯顿担任助理教授,同时也是Together AI的联合创始人兼首席科学家。
他更广为人知的身份是FlashAttention的发明者——这个几乎被所有主流AI框架集成的算法,直接改变了Transformer模型的训练和推理方式。2025年,他获得了Schmidt Sciences颁发的AI2050 Fellowship。

另一位指导者Albert Gu,华裔,CMU机器学习系助理教授,同时也是语音AI公司Cartesia的联合创始人兼首席科学家。
2024年,他被TIME杂志评选为「AI领域100位最具影响力人物」。
在X上,他的个人简介写着「leading the SSM revolution」(引领SSM革命),两年多内监督了Mamba三代架构的诞生。
可以说,整个SSM革命的理论根基,就是由这位华人学者一手奠定的。

参考资料:
https://venturebeat.com/technology/open-source-mamba-3-arrives-to-surpass-transformer-architecture-with-nearly
https://x.com/_albertgu/status/2033948415139451045?s=20
https://arxiv.org/pdf/2603.15569
文章来自于“新智元”,作者 “好困 桃子”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
