

为什么李飞飞团队经常cue通义千问?
为什么李飞飞团队经常cue通义千问?Qwen 3还未发布,但已发布的Qwen系列含金量还在上升。2个月前,李飞飞团队基于Qwen2.5-32B-Instruct 模型,以不到50美元的成本训练出新模型 S1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果。如今,他们的视线再次投向了这个国产模型。
来自主题: AI资讯
9337 点击 2025-04-12 12:02
Qwen 3还未发布,但已发布的Qwen系列含金量还在上升。2个月前,李飞飞团队基于Qwen2.5-32B-Instruct 模型,以不到50美元的成本训练出新模型 S1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果。如今,他们的视线再次投向了这个国产模型。
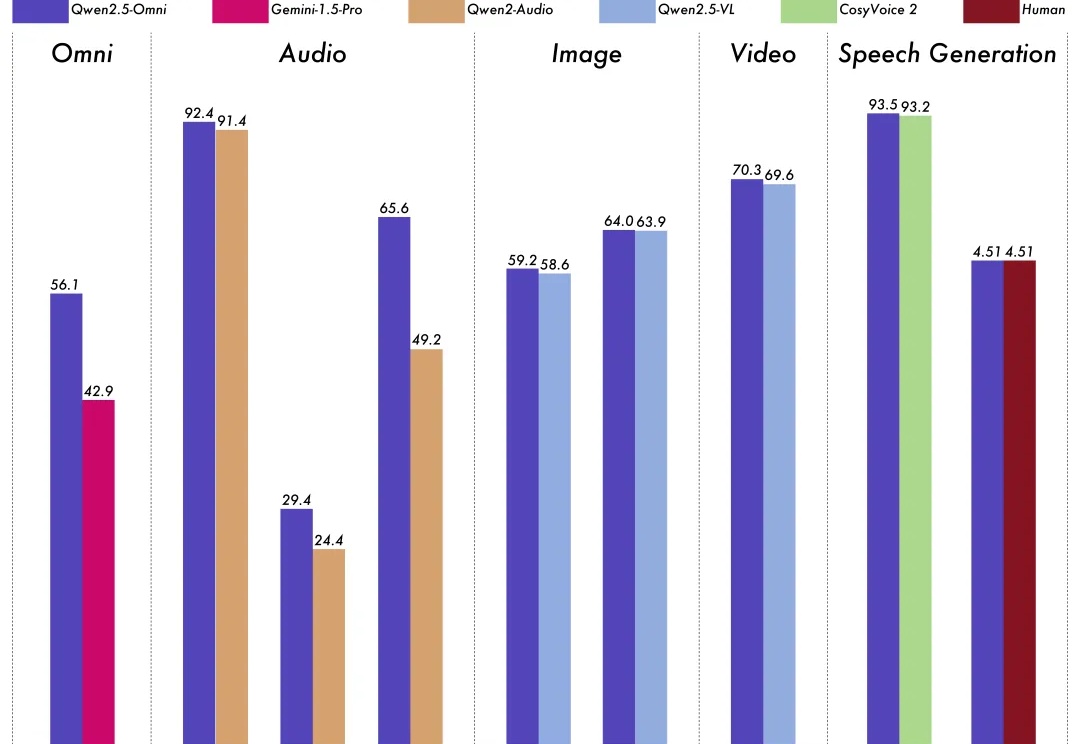
深夜重磅!阿里发布并开源首个端到端全模态大模型——
3 月 27 日凌晨,阿里通义千问团队发布 Qwen2.5-Omni。
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——

今天,百图生科宣布开源其领先的xTrimo V2中的蛋白质语言模型xTrimoPGLM,7个不同参数量的模型均已发布在huggingface和github,供全球用户自由获取和使用。xTrimoPGLM是全球首个千亿参数的蛋白质语言模型,性能超越了ESM-2、ProGen2等此前业界领先的蛋白质模型,并在药物分子设计和优化、抗体工程与疫苗开发、酶工程和生物催化剂设计等领域展现出广泛应用前景。

本文介绍了Search-R1技术,这是一项通过强化学习训练大语言模型进行推理并利用搜索引擎的创新方法。实验表明,Search-R1在Qwen2.5-7B模型上实现了26%的性能提升,使模型能够实时获取准确信息并进行多轮推理。本文详细分析了Search-R1的工作原理、训练方法和实验结果,为AI产品开发者提供了重要参考。
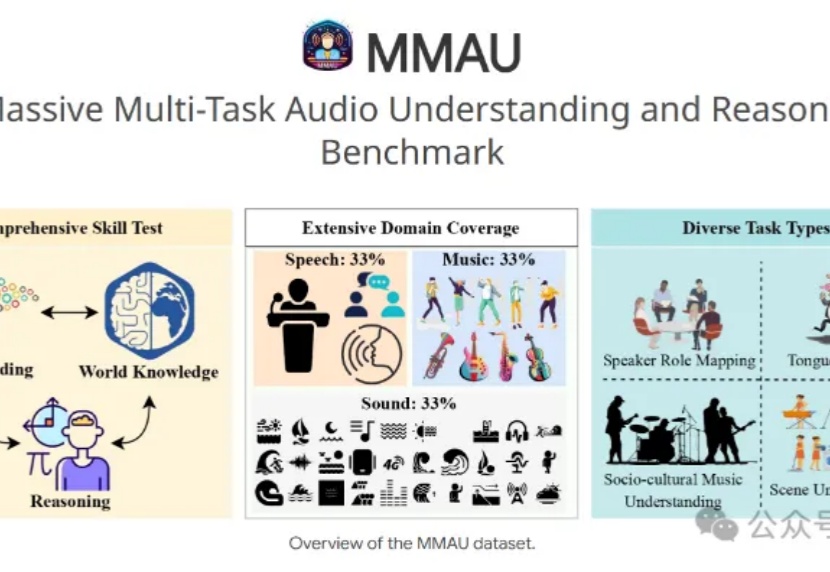
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

国产人形机器人,又上大分了。

日前,阿里国际站总裁张阔在接受《南华早报》等多家外媒专访时透露,面向海外买家推出的AI搜索引擎Accio企业用户已超百万。2月,阿里国际站的全线AI产品相继接入Qwen2.5、DeepSeek等先进推理模型,尤其是原生AI应用Accio的推出,让阿里国际站的AI应用引发全球高度关注。
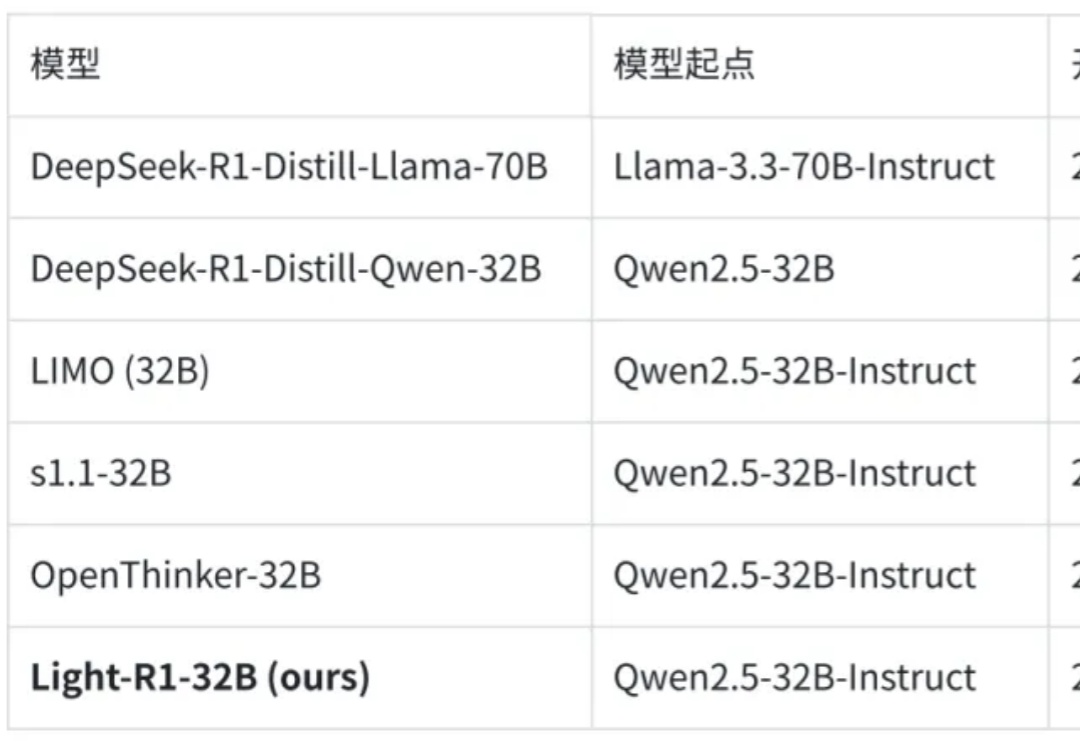
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B