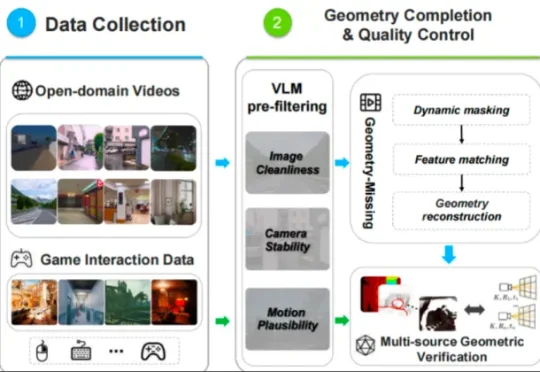
刚刚,全球首个超高帧世界模型MoWorld诞生!英伟达含量0,狂飙50帧
刚刚,全球首个超高帧世界模型MoWorld诞生!英伟达含量0,狂飙50帧专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。
来自主题: AI资讯
9694 点击 2026-07-08 16:00
 搜索
搜索
专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。
Claude立大功!开发者靠它剖析MIL语言与E5二进制,绕过CoreML直达硬件,证明NPU训练从来不是硬件不行,而是苹果不让用。

打造 AI 时代计算效率的新标杆。

从手机、PC、汽车到机器人,我们需要怎样的端侧AI "芯" 思路? 作者 | 云鹏 编辑 | 漠影 机器人走猫步引爆行业、舞蹈功夫如人类般丝滑;AI手机一句话订外卖做报告、懂你所想知你所言;AI PC
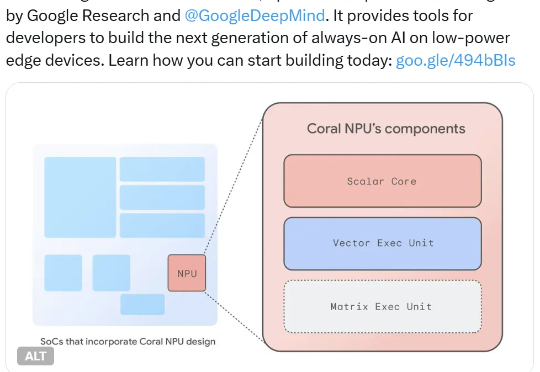
他们又推出了 Coral NPU,可用于构建在低功率设备上持续运行的 AI。具体来说,其可在可穿戴设备上运行小型 Transformer 模型和 LLM,并可通过 IREE 和 TFLM 编译器支持 TensorFlow、JAX 和 PyTorch。

天玑9500围绕这一目标重构芯片底座:首发双NPU架构,结合存算一体、硬件压缩等多项关键技术,在ETHZ苏黎世移动SoC AI榜单中蝉联榜首,相比上一代跑分翻倍。
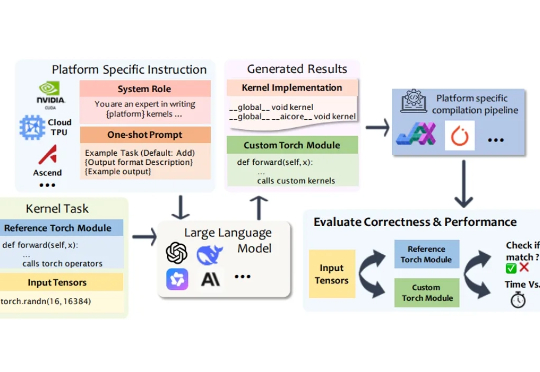
在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。

NPU很好,但用不上。 我知道现在风口是 AI ,自家产品不沾点 AI 都不好意思拿出手 —— 但你们这些 “ AIPC ” 的宣传,是不是有点过了?

AMD携手Stability AI宣布推出世界首款适用于Stable Diffusion 3.0 Medium的B16 NPU模型。该模型可直接运行于AMD XDNA 2 NPU之上,能够显著提升图像生成质量。新模型作为Amuse 3.1平台的组件之一亮相,于今天一起发布。
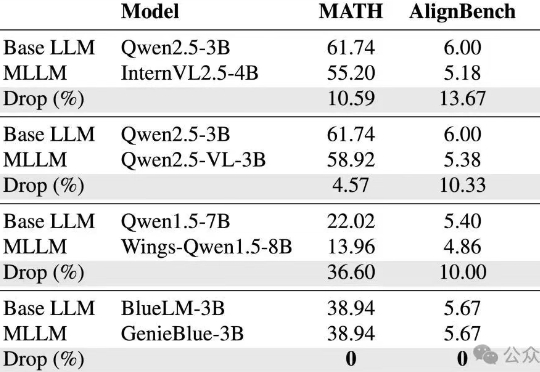
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。